最近两天领了一个活,定位项目中一个job的告警原因。
任务背景:这个job是每晚定时运行,job大体功能是多进程分片(最大同时有8个进程)去循环连接各个分库(库的数量数以万计),进入分库后,再进行两层循环的计算(总共三层循环),此job运行五分钟之后,总会时不时报,找不到分库数据源(但是实际上去db中查找,有些是脏的分库真不存在,但是有的数据源确实真存在)
定位方法&过程:
- 既然告警当中确有不存在的数据源,会不会是其中一个分片进程循环遇到找不到的数据源而引起后面的连接出错的连锁反应呢?
于是决定写一个脚本,把所有确不存在的脏数据源给理出来,然后统一在外层过滤掉,使得每个分片逻辑中不会去连脏的数据源 - 当我完成上一步清理掉脏数据源后,再次跑了下这个job, 这次依旧是跑了五分钟后抛出几百封告警邮件,随机抽查了下,这次告警连不上的数据源都是存在的
那么问题出在哪呢?只能详细去查代码定位了 🙁
<?php
//伪代码如下
...
//如果缓存数据源池里存在此数据源名,则直接从中取
if ($name存在于缓存的连接池中) {
$conn = 缓存连接池里取出传入的连接名的数据库配置;
} elseif (属于指定环境) {
$conn = 重新从数据源配置表里读取配置($name);
} else {
$conn = null;
}
if (empty($conn)) {
抛异常("数据源名:" . $name...);
....
}
...
?>根据报错,是走进了empty conn逻辑,然后抛异常出来。那么问题来了,上面有if, elseif, else三个分支逻辑,究竟走到哪个分支逻辑,使得conn为空呢,目测的话,有可能走进elseif ,也有可能是走过了else逻辑,为了先确认这个问题,我把代码改了一下:
<?php
//伪代码如下
...
//如果缓存数据源池里存在此数据源名,则直接从中取
if ($name存在于缓存的连接池中) {
$flag = 1;
$conn = 缓存连接池里取出传入的连接名的数据库配置;
} elseif (属于指定环境) {
$flag = 2;
$conn = 重新从数据源配置表里读取配置($name);
} else {
$flag = 3;
$conn = null;
}
if (empty($conn)) {
//之所以在这里重定向,而不在上面分支逻辑中埋log, 是因为上面的逻辑if elseif是正常逻辑,所有的正常业务,也可能会走到,会产生不必要的log
error_log("empty conn, flag:" . $flag, 3, "/tmp/empty_conn.log");
抛异常("数据源名:" . $name...);
....
}
...
?>按照上面的代码,就知道走哪个分支逻辑使得conn变量为空了,这样便可以进一步知道null的来源,结论:定位到是else逻辑“$conn = 重新从数据源配置表里读取配置($name);”导致conn为空的。
紧接着查看“ 重新从数据源配置表里读取配置 ”这个方法,此方法主要是根据name传参查出数据源。
在此方法中再次埋了下log, 在mysqli_connect连接后打印了mysqli_errorno和mysqli_error()
mysqli_error()返回的信息是: “Cannot assign requested address“,其实这里面埋log 也一波三折,具体过程就不细聊了。
下面来看一下”Cannot assgin requested address”的原因分析:
“Cannot assign requested address.”是由于linux分配的客户端连接端口用尽,无法建立socket连接所致,虽然socket正常关闭,但是端口不是立即释放,而是处于TIME_WAIT状态,默认等待60s后才释放。为什么会用尽呢?通常这个情况出现在高并发数据库又是短连接,端口迅速被分配完,虽然代码层有mysql close 但是端口并不会快速被释放,所以就出现了此问题。
如何解决, 网上查了下解决方案:
解决方法1–调低time_wait状态端口等待时间:
- 调低端口释放后的等待时间,默认为60s,修改为15~30s
sysctl -w net.ipv4.tcp_fin_timeout=30 - 修改tcp/ip协议配置, 通过配置/proc/sys/net/ipv4/tcp_tw_resue, 默认为0,修改为1,释放TIME_WAIT端口给新连接使用
sysctl -w net.ipv4.tcp_timestamps=1 - 修改tcp/ip协议配置,快速回收socket资源,默认为0,修改为1
sysctl -w net.ipv4.tcp_tw_recycle=1
解决办法2–增加可用端口:
shell> $ sysctl -a | grep port_range
net.ipv4.ip_local_port_range = 50000 65000 -----意味着50000~65000端口可用 修改参数:
$ vi /etc/sysctl.conf
net.ipv4.ip_local_port_range = 10000 65000 -----意味着10000~65000端口可用改完后,执行命令“sysctl -p”使参数生效,不需要reboot
但是我没有按照上面的方案来优化,原因主要是:
我再次跑了下此job, 告警的时候,我观察了下netstat -an | grep TIME_WAIT | wc -l, 结果一度飙到6w多,所以爆了,job一度告警,不仅这个job, 其他同时间的job也受到牵连,根据经验,闲时的并发量,一般达不到这个值。代码应该写的有些许问题。但是目前不想去改代码,因为改代码:一,需要时间;二,需要验证。
我做了如下几点优化:
- 查数据库源配置信息的方法,之前每次循环查一次就连一次db,我将连db这里做成了单例,第二次循环之后,用的是前一次连接句柄。 接着观察了下db的tcp连接数,已经较之前下降了一半, 但是按照上面的修改,仍然不能满足要求,试了下单纯只跑这个job 虽然不会告警,但是如果同一时间有其他job也在跑的话,很可能还会告警,TIME_WAIT仍然会很高。
- 降低此job总的并发进程数
- 限制此job在每台job机上的运行个数
通过上面三个优化手段之后,再次跑了下此job,并且是模拟正常job量的情况下运行的,发现已经没有告警了。当然后续可以对此脚本再优化,也是能起到一定效果的。
再次查资料查了下TIME_WAIT相关资料:
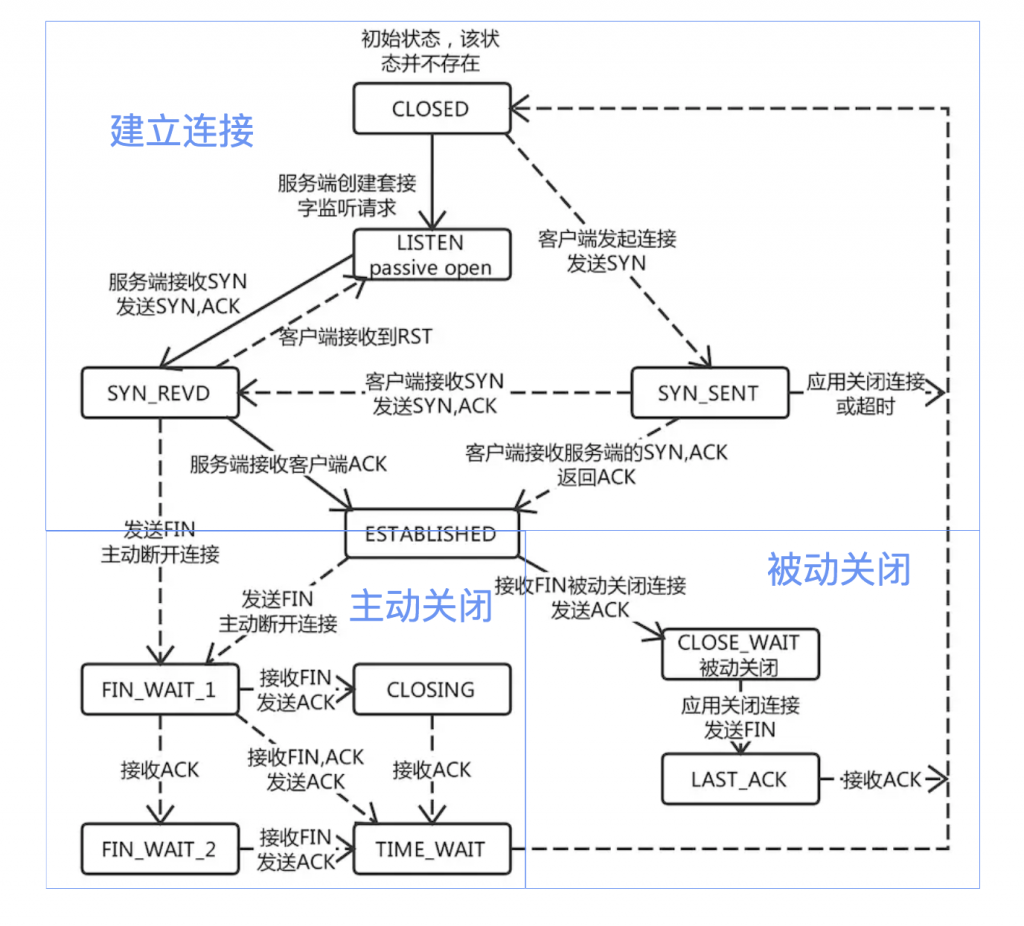
一眼看过去,这么多状态,各个方向的连线,但是整个图可以被划分为三个部分,上半部是建立连接的过程,左下部是主动关闭连接,右下部是被动关闭连接的过程。
从上图可以看出来,当TCP连接主动关闭时,会经过TIME_WAIT状态,所以TIME_WAIT状态是TCP四次握手结束后,连接双方都不再交换消息,但主动关闭的一方保持这个连接一段时间内不可用。
那这个TIME_WAIT状态有什么用呢?
暂以 A、B 来代指 TCP 连接的两端,A 为主动关闭的一端。
四次挥手中,A 发 FIN, B 响应 ACK,B 再发 FIN,A 响应 ACK 实现连接的关闭。而如果 A 响应的 ACK 包丢失,B 会以为 A 没有收到自己的关闭请求,然后会重试向 A 再发 FIN 包。
如果没有 TIME_WAIT 状态,A 不再保存这个连接的信息,收到一个不存在的连接的包,A 会响应 RST 包,导致 B 端异常响应。
此时, TIME_WAIT 是为了保证全双工的 TCP 连接正常终止。
允许老的重复分节在网络中消逝:
我们还知道,TCP 下的 IP 层协议是无法保证包传输的先后顺序的。如果双方挥手之后,一个网络四元组(src/dst ip/port)被回收,而此时网络中还有一个迟到的数据包没有被 B 接收,A 应用程序又立刻使用了同样的四元组再创建了一个新的连接后,这个迟到的数据包才到达 B,那么这个数据包就会让 B 以为是 A 刚发过来的。
此时, TIME_WAIT 的存在是为了保证网络中迷失的数据包正常过期。
那TIME_WAIT的时长是多少呢?
TIME_WAIT的过期时间,MSL(最大分段寿命,Maximum Segment Lifetime),它表示一个TCP分段可以存在于互联网系统中的最大时间,由TCP的实现,超出这个寿命的分片就会被丢弃。
TIME_WAIT 状态由主动关闭的 A 来保持,那么我们来考虑对于 A 来说,可能接到上一个连接的数据包的最大时长:A 刚发出的数据包,能保持 MSL 时长的寿命,它到了 B 端后,B 端由于关闭连接了,会响应 RST 包,这个 RST 包最长也会在 MSL 时长后到达 A,那么 A 端只要保持 TIME_WAIT 到达 2MSL 就能保证网络中这个连接的包都会消失。
MSL 的时长被 RFC 定义为 2分钟,但在不同的 unix 实现上,这个值不并确定,我们常用的 centOS 上,它被定义为 30s,我们可以通过 /proc/sys/net/ipv4/tcp_fin_timeout 这个文件查看和修改这个值。2MSL就是60s.
大量TIME_WAIT造成的影响:
在高并发短连接的TCP服务器上,当服务器处理完请求后立刻主动正常关闭连接。这个场景下会出现大量socket处于TIME_WAIT状态。如果客户端的并发量持续很高,此时部分客户端就会显示连接不上。
主动正常关闭TCP连接,都会出现TIMEWAIT。
为什么我们要关注这个高并发短连接呢?有两个方面需要注意:
- 高并发可以让服务器在短时间范围内同时占用大量端口,而端口有个0~65535的范围,并不是很多,刨除系统和其他服务要用的,剩下的就更少了。
- 在这个场景中,短连接表示”业务处理+传输数据的时间 远远小于 TIMEWAIT超时的时间”的连接。
这里有个相对长短的概念,比如取一个web页面,1秒钟的http短连接处理完业务,在关闭连接之后,这个业务用过的端口会停留在TIMEWAIT状态几分钟,而这几分钟,其他HTTP请求来临的时候是无法占用此端口。