You can search any field by typing the field name followed by a colon “:” and then the term you are looking for.
title:"The Right Way" AND text:go
title:"Do it right" AND right
Wildcard Searches 通配符查找
The single character wildcard search looks for terms that match that with the single character replaced. For example, to search for “text” or “test” you can use the search:
where the status field contains active
status:active
where the title field contains quick or brown. If you omit the OR operator the default operator will be used
title:(quick OR brown)
title:(quick brown)
where the author field contains the exact phrase "john smith"
author:"John Smith"
Regular expression patterns can be embedded in the query string by wrapping them in forward-slashes ("/"):
name:/joh?n(ath[oa]n)/
Ranges can be specified for date, numeric or string fields. Inclusive ranges are specified with square brackets [min TO max] and exclusive ranges with curly brackets {min TO max}.
count:[1 TO 5]
date:[2012-01-01 TO 2012-12-31]
Dates before 2012
date:{* TO 2012-01-01}
时间范围查询
created:["2020-06-15 22:00:00" TO "2020-06-16 10:00:00"]
We can search for terms that are similar to, but not exactly like our search terms, using the “fuzzy” operator:
quikc~ brwn~ foks~
This uses the Damerau-Levenshtein distance to find all terms with a maximum of two changes, where a change is the insertion, deletion or substitution of a single character, or transposition of two adjacent characters.
The default edit distance is 2, but an edit distance of 1 should be sufficient to catch 80% of all human misspellings. It can be specified as:
#检查jdk环境,需要jdk1.8+
java -version
#解压安装包
tar -xvzf logstash-6.2.4.tar.gz
在聊示例之前,再聊一会儿logstash的理论
A Logstash pipeline has two required elements, input and output, and one optional element, filter. The input plugins consume data from a source, the filter plugins modify the data as you specify, and the output plugins write the data to a destination.
The -e flag enables you to specify a configuration directly from the command line. Specifying configurations at the command line lets you quickly test configurations without having to edit a file between iterations. The pipeline in the example takes input from the standard input, stdin, and moves that input to the standard output, stdout, in a structured format.
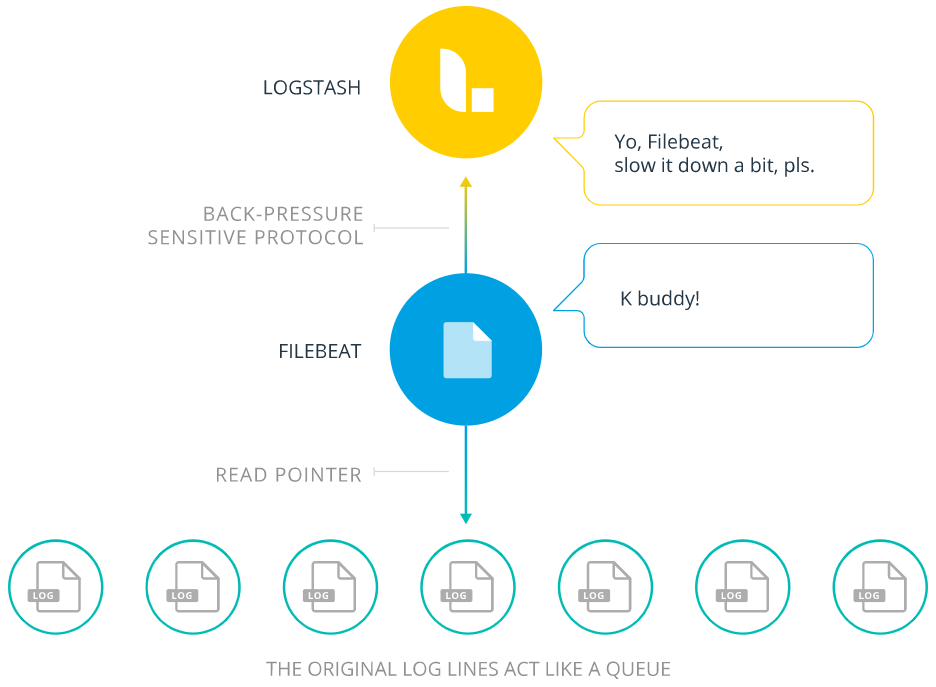
Here’s how Filebeat works: When you start Filebeat, it starts one or more inputs that look in the locations you’ve specified for log data. For each log that Filebeat locates, Filebeat starts a harvester(中文被翻成收割机). Each harvester reads a single log for new content and sends the new log data to libbeat, which aggregates the events and sends the aggregated data to the output that you’ve configured for Filebeat.
What is a harvester?
A harvester is responsible for reading the content of a single file. The harvester reads each file, line by line, and sends the content to the output. One harvester is started for each file. The harvester is responsible for opening and closing the file, which means that the file descriptor remains open while the harvester is running. If a file is removed or renamed while it’s being harvested, Filebeat continues to read the file. This has the side effect that the space on your disk is reserved until the harvester closes. By default, Filebeat keeps the file open until close_inactive is reached.
[root@VM_IP_centos filebeat-6.2.4]# ./filebeat -e -c test.yml
2020-06-13T06:40:22.290+0800 INFO instance/beat.go:468 Home path: [/opt/filebeat-6.2.4] Config path: [/opt/filebeat-6.2.4] Data path: [/opt/filebeat-6.2.4/data] Logs path: [/opt/filebeat-6.2.4/logs]
2020-06-13T06:40:22.290+0800 INFO instance/beat.go:475 Beat UUID: d29dba4a-be63-483a-8d15-35d78f1fa68e
2020-06-13T06:40:22.290+0800 INFO instance/beat.go:213 Setup Beat: filebeat; Version: 6.2.4
2020-06-13T06:40:22.290+0800 INFO pipeline/module.go:76 Beat name: VM_16_5_centos
2020-06-13T06:40:22.290+0800 INFO instance/beat.go:301 filebeat start running.
2020-06-13T06:40:22.290+0800 INFO registrar/registrar.go:73 No registry file found under: /opt/filebeat-6.2.4/data/registry. Creating a new registry file.
2020-06-13T06:40:22.291+0800 INFO [monitoring] log/log.go:97 Starting metrics logging every 30s
2020-06-13T06:40:22.298+0800 INFO registrar/registrar.go:110 Loading registrar data from /opt/filebeat-6.2.4/data/registry
2020-06-13T06:40:22.298+0800 INFO registrar/registrar.go:121 States Loaded from registrar: 0
2020-06-13T06:40:22.298+0800 WARN beater/filebeat.go:261 Filebeat is unable to load the Ingest Node pipelines for the configured modules because the Elasticsearch output is not configured/enabled. If you have already loaded the Ingest Node pipelines or are using Logstash pipelines, you can ignore this warning.
2020-06-13T06:40:22.298+0800 INFO crawler/crawler.go:48 Loading Prospectors: 1
2020-06-13T06:40:22.298+0800 INFO crawler/crawler.go:82 Loading and starting Prospectors completed. Enabled prospectors: 1
2020-06-13T06:40:22.298+0800 INFO log/harvester.go:216 Harvester started for file: -
#Harvester started for file 表示filebeat已经启动
hello #这里是我在命令行的一个输入
{
"@timestamp": "2020-06-12T22:40:38.439Z",
"@metadata": {
"beat": "filebeat",
"type": "doc",
"version": "6.2.4"
},
"message": "hello",
"prospector": {
"type": "stdin"
},
"beat": {
"name": "VM_IP_centos",
"hostname": "VM_IP_centos",
"version": "6.2.4"
},
"source": "",
"offset": 6
}
#filebeat两个启动参数
-c, --c string Configuration file, relative to path.config (default "filebeat.yml")
--cpuprofile string Write cpu profile to file
-e, --e Log to stderr and disable syslog/file output (输出到标准输出,默认输出到syslog和logs下)
-d, -d "publish" 输出debug信息
#启动
[root@VM_IP_centos filebeat-6.2.4]# ./filebeat -e -c test.yml
2020-06-13T07:06:49.189+0800 INFO instance/beat.go:468 Home path: [/opt/filebeat-6.2.4] Config path: [/opt/filebeat-6.2.4] Data path: [/opt/filebeat-6.2.4/data] Logs path: [/opt/filebeat-6.2.4/logs]
2020-06-13T07:06:49.189+0800 INFO instance/beat.go:475 Beat UUID: d29dba4a-be63-483a-8d15-35d78f1fa68e
2020-06-13T07:06:49.189+0800 INFO instance/beat.go:213 Setup Beat: filebeat; Version: 6.2.4
2020-06-13T07:06:49.190+0800 INFO pipeline/module.go:76 Beat name: VM_16_5_centos
2020-06-13T07:06:49.190+0800 INFO instance/beat.go:301 filebeat start running.
2020-06-13T07:06:49.190+0800 INFO registrar/registrar.go:110 Loading registrar data from /opt/filebeat-6.2.4/data/registry
2020-06-13T07:06:49.190+0800 INFO registrar/registrar.go:121 States Loaded from registrar: 0
2020-06-13T07:06:49.190+0800 WARN beater/filebeat.go:261 Filebeat is unable to load the Ingest Node pipelines for the configured modules because the Elasticsearch output is not configured/enabled. If you have already loaded the Ingest Node pipelines or are using Logstash pipelines, you can ignore this warning.
2020-06-13T07:06:49.190+0800 INFO crawler/crawler.go:48 Loading Prospectors: 1
2020-06-13T07:06:49.190+0800 INFO log/prospector.go:111 Configured paths: [/tmp/logs/*.log]
2020-06-13T07:06:49.190+0800 INFO crawler/crawler.go:82 Loading and starting Prospectors completed. Enabled prospectors: 1
2020-06-13T07:06:49.190+0800 INFO [monitoring] log/log.go:97 Starting metrics logging every 30s
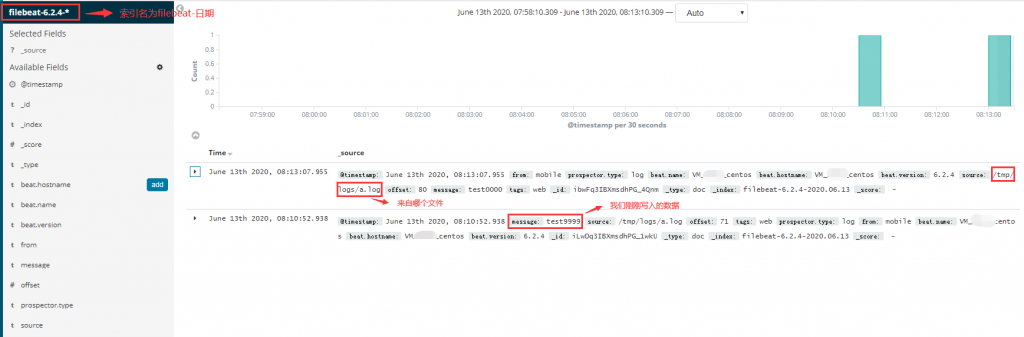
2020-06-13T07:06:49.191+0800 INFO log/harvester.go:216 Harvester started for file: /tmp/logs/a.log
#Harvester started for files: /tmp/logs/a.log 表示已经感知到我们设置的log文件
(2) ERROR: [2] bootstrap checks failed [1]: max number of threads [3881] for user [esuser] is too low, increase to at least [4096] [2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
#解决方案
vim /etc/security/limits.d/20-nproc.conf
* soft nproc 4096
* hard nproc 4096
//或者将*号改成esuser
//是否生效与否,可以切esuser,然后ulimit -a查看"max user processes"是否达到4096
在/etc/sysctl.conf添加vm.max_map_count
echo "vm.max_map_count=262144" > /etc/sysctl.conf
sysctl -p