文章来源: https://www.jianshu.com/p/9fae09876eb7 (这是我迄今为止看到讲k8s 讲的比较的好的一篇文章),即便你刚刚接触k8s, 看完他,也能减少很多疑惑
挡在Pod前面的Service
第一个疑问:有了Pod,让它们互相访问就可以了,为什么还需要type=Service类型的Service对象呢?答案是:不可以,因为Pod是有生命周期的,他可能随时被创建也可能随时销毁,而每次新建Pod, 都是随机分配IP的。并且k8s会自动调控Pod数量,这就导致Pod之间直接访问不太现实,如果有一个入口,可以动态绑定那些相同服务的Pod,并将其开放在固定端口上,这样访问起来就方便多了,这个入口在k8s中被称为service, 简称为svc。
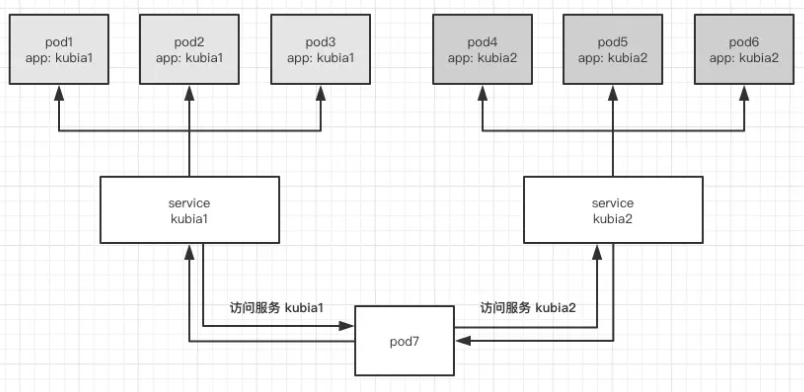
svc不会自己提供服务,他身后一定要有实质的应用来提供服务(不一定是Pod), 我们用rs来创建Pod也是可以的
先创建一个kubia-replicaset.yaml,并填入如下内容:
apiVersion: apps/v1beta2
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
ports:
- containerPort: 8080这个文件将创建3个Pod,每个Pod都包含一个app: kubia的标签,并开放提供服务的8080端口。执行如下命令进行创建:
kubectl create -f kubia-replicaset.yaml然后kubectl get pods 可以看到创建出的三个pod,接下来我们创建一个svc来提供对这三个pod来访问。新建kubia-svc.yaml文件,并填入如下内容:
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
ports:
- name: http # 请为所有端口指定名称
port: 80 # 对外开放的服务端口
targetPort: 8080 # 后方 pod 的服务端口
selector:
app: kubia可以看到基本svc的配置非常简单,只定义了两个端口和一个选择器,我们在选择器中注明了app: kubia,意思就是让这个svc去将所有携带app:kubia标签的pod 纳入自己的后方。ports.name不是必填项,但是为了方便维护,请为每个端口指定名称。然后使用下面的命令创建svc
kubectl create -f创建好了之后来看一下,执行kubectl get svc kubia,我们可以看到svc的信息:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubia ClusterIP 10.98.237.175 <none> 80/TCP 127m可以在custer-ip列看到当前ip地址,其他的pod 就是通过这个ip访问到其后面的pod。接下来我们随便使用一个pod 访问这个服务。
kubectl exec kubia-7rt2n -- curl -s 10.98.237.175这条命令里的–是一个分隔符,之前的部分是属于kubectl的,之后是属于要在pod内部执行的命令。
然后可以看到来自service后方pod的响应
root@master1:~# kubectl exec kubia-7rt2n -- curl -s 10.98.237.175
You've hit kubia-pxfw7
root@master1:~# kubectl exec kubia-7rt2n -- curl -s 10.98.237.175
You've hit kubia-7rt2n
root@master1:~# kubectl exec kubia-7rt2n -- curl -s 10.98.237.175
You've hit kubia-7rt2n
root@master1:~# kubectl exec kubia-7rt2n -- curl -s 10.98.237.175
You've hit kubia-fxqcc我们可以看到,service同时也实现了负载均衡,合理的将请求平摊到每个pod上了。
Service对pod的动态绑定
因为svc是通过我们事先定义好的标签选择器来查找 pod 的,所以 pod 的 ip 地址变动对于svc毫无影响,其实在svc和pod之间还包含了一个资源叫做endpoint(这个我再另一篇文章里有介绍),endpoint(简称ep)是一组地址及其端口的合集,如下图,只要一个svc有标签选择器的话,他就会自动创建一个同名的ep来标记出自己的要管理的 pod。
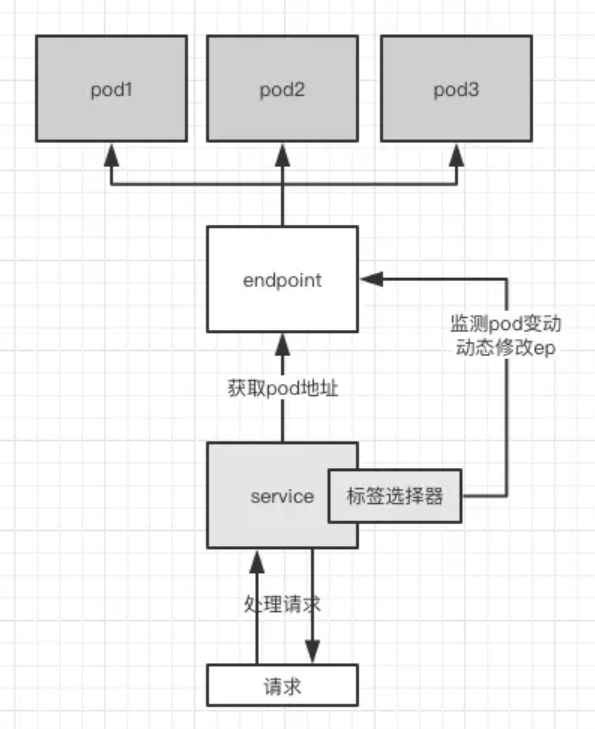
我们可以通过如下的命令来查看我们刚创建的kubia服务的ep
root@master1:~# kubectl describe svc kubia
Name: kubia
Namespace: default
Labels: <none>
Annotations: <none>
Selector: app=kubia
Type: ClusterIP
IP: 10.98.237.175
Port: <unset> 80/TCP
TargetPort: 8080/TCP
Endpoints: 10.244.1.18:8080,10.244.2.14:8080,10.244.3.14:8080
Session Affinity: None
Events: <none>然后就可以在Endpoints列中找到他包含的地址及端口号,这三个用,分隔的地址正是三个 pod 的地址。你可以使用kubectl get pod -o wide来查看 pod 的地址。你可以执行如下命令来重建所有的kubia pod,然后再来查看ep,会发现其ep也会自动更换成这三个 pod 的值
kubectl delete po -l app=kubia
root@master1:~# kubectl get endpoints kubia
NAME ENDPOINTS AGE
kubia 10.244.1.18:8080,10.244.2.14:8080,10.244.3.14:8080 169m服务发现
你可能已经发现了,在上文的测试中,我们使用了curl http://x.x.x.x的方式访问的svc,这样的话如果svc重建导致 ip 地址改变了,那我们岂不是访问不到了?k8s 也想到了这一点,所以提供了通过FQDN(全限定域名)访问服务的方式,你可以在任意一个 pod 上直接使用服务的名称来访问服务:
root@master1:~# k exec kubia-5n2m2 -- curl -s http://kubia
You've hit kubia-bv2k8这种方式可以访问同一命名空间中的服务,k8s 也支持访问其他命名空间的服务。不过域名要长很多。有兴趣的话可以自行了解。
如果你发现你访问不到服务的话请使用kubectl delete po -l app=kubia重建 pod。因为 k8s 只会在创建时间晚于服务的 pod 中注入服务域名。你可以在容器中查看/etc/resolv.conf文件来找到对应的解析。
顺带一提,这个功能是 k8s 的 dns 服务器coredns实现的,你可以在命名空间kube-system中找到它。
访问集群外部的服务:ep
可以查看我的另一篇文章: https://www.clarkhu.net/?p=4614
以上就是k8s中,服务之间是如何沟通的