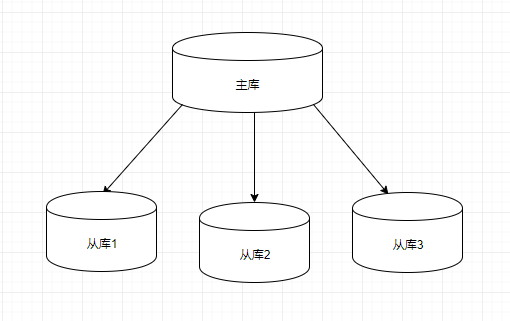
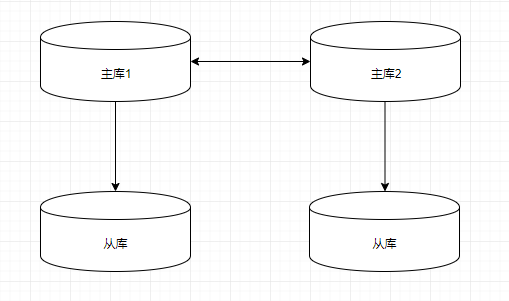
最近在做数据库实例切换,接触到amoeba,于是稍加学习了一下,先介绍一下,什么是Amoeba?
Amoeba一共有三个项目产品:
Amoeba for MySQL:
为MySQL提供了一种数据库代理的解决方案,可以实现多台MySQL之间的读写分离,具有负载均衡、高可用性、Query过滤、读写分离、可路由相关的query到目标数据库、可并发请求多台数据库合并结果。 在Amoeba上面你能够完成多数据源的高可用、负载均衡、数据切片的功能。
Amoeba for Aladdin:
类似“Amoeba for MySQL”,不同的是“Amoeba for MySQL”只支持MySQL数据库,“Amoeba for Aladdin”支持多种数据库,同时还可以在后台使用多种混合数据库。
Amoeba for MongoDB:
实现对NoSQL数据库MongoDB的代理功能,具备心跳检测、负载均衡、故障转移、查询聚合等功能。
从目前Amoeba的系列产品来看,都是针对数据库存储应用在分布式群集负载场景下的解决方案,覆盖了常用的数据库种类。
Amoeba(变形虫)项目,该开源框架于2008年 开始发布一款 Amoeba for Mysql软件。 着重介绍下Amoeba for mysql, 这个软件致力于MySQL的分布式数据库前端代理层,它主要在应用层访问MySQL的时候充当SQL路由功能,专注于分布式数据库代理层(Database Proxy)开发。座落与 Client、DB Server(s)之间,对客户端透明。具有负载均衡、高可用性、SQL 过滤、读写分离、可路由相关的到目标数据库、可并发请求多台数据库合并结果。 通过Amoeba你能够完成多数据源的高可用、负载均衡、数据切片的功能,目前Amoeba已在很多 企业的生产线上面使用。
从上面这段话可以看出:Amoeba for mysql 主要是mysql的一个代理,主要是应用层访问mysql时充当sql路由。
大致查了一下,amoeba大概从2012年下旬之后,就不再更新了,是一个非常老的开源项目,并且资料比较少,出于现有项目有使用到这个代理,只能硬着头皮啃了.
- Amoeba安装
详见这篇文档:http://wiki.hexnova.com/pages/viewpage.action?pageId=2031909
- 安装Java, Amoeba框架是基于Java SE1.6开发的,建议使用Java SE 1.6版本。java -version
java version “1.6.0_18” - http://sourceforge.net/projects/amoeba/files/ Amoeba源码下载
- 下载后存放并解压到安装的位置。这里假设你将存档文件解压到/usr/local/amoeba-mysql-binary-2.0.1-BETA,解压到其他路径也是一样的。进入Ameoba运行目录:[]$ cd AMOEBA_HOME=/usr/local/amoeba-mysql-binary-2.0.1-BETA/bin
- 验证: amoeba start|stop
- Amoeba 基础入门
详细参考:http://wiki.hexnova.com/pages/viewpage.action?pageId=2031911
Amoeba基础配置介绍
Amoeba有哪些主要的配置文件?
- 想象Amoeba作为数据库代理层,它一定会和很多数据库保持通信,因此它必须知道由它代理的数据库如何连接,比如最基础的:主机IP、端口、Amoeba使用的用户名和密码等等。这些信息存储在$AMOEBA_HOME/conf/dbServers.xml中。
- Amoeba为了完成数据切分提供了完善的切分规则配置,为了了解如何分片数据、如何将数据库返回的数据整合,它必须知道切分规则。与切分规则相关的信息存储在$AMOEBA_HOME/conf/rule.xml中。
- 当我们书写SQL来操作数据库的时候,常常会用到很多不同的数据库函数,比如:UNIX_TIMESTAMP()、SYSDATE()等等。这些函数如何被Amoeba解析呢?$AMOEBA_HOME/conf/functionMap.xml描述了函数名和函数处理的关系。
- 对$AMOEBA_HOME/conf/rule.xml进行配置时,会用到一些我们自己定义的函数,比如我们需要对用户ID求HASH值来切分数据,这些函数在$AMOEBA_HOME/conf/ruleFunctionMap.xml中定义。
- Amoeba可以制定一些可访问以及拒绝访问的主机IP地址,这部分配置在$AMOEBA_HOME/conf/access_list.conf中
- Amoeba允许用户配置输出日志级别以及方式,配置方法使用log4j的文件格式,文件是$AMOEBA_HOME/conf/log4j.xml。
配置一个db节点, 使用Amoeba做操作转发的步骤:
1. 首先,在$AMOEBA_HOME/conf/dbServers.xml中配置一台数据库,如下:
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE amoeba:dbServers SYSTEM "dbserver.dtd">
<amoeba:dbServers xmlns:amoeba="http://amoeba.meidusa.com/">
<!--
Each dbServer needs to be configured into a Pool,
If you need to configure multiple dbServer with load balancing that can be simplified by the following configuration:
add attribute with name virtual = "true" in dbServer, but the configuration does not allow the element with name factoryConfig
such as 'multiPool' dbServer
-->
<dbServer name="abstractServer" abstractive="true">
<factoryConfig class="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory">
<property name="manager">${defaultManager}</property>
<property name="sendBufferSize">64</property>
<property name="receiveBufferSize">128</property>
<!-- mysql port -->
<property name="port">3306</property>
<!-- mysql schema -->
<property name="schema">test</property>
<!-- mysql user -->
<property name="user">root</property>
<!-- mysql password -->
<property name="password">password</property>
</factoryConfig>
<poolConfig class="com.meidusa.amoeba.net.poolable.PoolableObjectPool">
<property name="maxActive">500</property>
<property name="maxIdle">500</property>
<property name="minIdle">10</property>
<property name="minEvictableIdleTimeMillis">600000</property>
<property name="timeBetweenEvictionRunsMillis">600000</property>
<property name="testOnBorrow">true</property>
<property name="testWhileIdle">true</property>
</poolConfig>
</dbServer>
<dbServer name="server1" parent="abstractServer">
<factoryConfig>
<!-- mysql ip -->
<property name="ipAddress">127.0.0.1</property>
</factoryConfig>
</dbServer>
<dbServer name="multiPool" virtual="true">
<poolConfig class="com.meidusa.amoeba.server.MultipleServerPool">
<!-- Load balancing strategy: 1=ROUNDROBIN , 2=WEIGHTBASED , 3=HA-->
<property name="loadbalance">1</property>
<!-- Separated by commas,such as: server1,server2,server1 -->
<property name="poolNames">server1</property>
</poolConfig>
</dbServer>
</amoeba:dbServers>以下对这个简单的配置文件进行一些分析:
这份dbServers配置文件中,我们定义了三个dbServer元素,这是第一个dbServer元素的定义。这个名为abstractServer的dbServer,其abstractive属性为true,这意味着这是一个抽象的dbServer定义,可以由其他dbServer定义拓展。
在第一个dbServer元素分别定义MySQL的端口号、数据库名、用户名以及密码。
manager定义了该dbServer选择的连接管理器(ConnectionManager),这里引用了amoeba.xml的配置,稍后介绍。
dbServer下有poolConfig的元素,这个元素的属性主要配置了与数据库的连接池,与此相关的具体配置会在后面的章节中详细介绍。
命名为server1的dbServer元素,正如你设想的那样,这个server1是abstractServer的拓展,parent属性配置了拓展的抽象dbServer,它拓展了abstractServer的ipAddress属性来指名数据库的IP地址,而在端口、用户名密码、连接池配置等属性沿用了abstractServer的配置。
server1拓展了abstractServer的ipAddress属性。
这一段其实并不需要配置,并不会影响到基本使用。以下大致介绍下此配置的含义:multiPool是一个虚拟的数据库节点,可以将这个节点配置成好几台数据库组成的数据库池。比如上面这个配置中仅配置了一台server1,负载均衡策略为ROUNDROBIN(轮询)。与虚拟数据库节点相关的详细教程会在后面的章节中介绍。
由此,你大概可以理解定义abstractServer的原因:当我们有一个数据库集群需要管理,这个数据库集群中节点的大部分信息可能是相同的,比如:端口号、用户名、密码等等。因此通过归纳这些共性定义出的abstractServer极大地简化了dbServers配置文件
2.配置amoeba.xml
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE amoeba:configuration SYSTEM "amoeba.dtd">
<amoeba:configuration xmlns:amoeba="http://amoeba.meidusa.com/">
<proxy>
<!-- service class must implements com.meidusa.amoeba.service.Service -->
<service name="Amoeba for Mysql" class="com.meidusa.amoeba.net.ServerableConnectionManager">
<!-- amoeba对外连接数据库时的端口 -->
<property name="port">8066</property>
<!-- amoeba对外连接数据库时的IP -->
<property name="ipAddress">127.0.0.1</property>
<property name="manager">${clientConnectioneManager}</property>
<property name="connectionFactory">
<bean class="com.meidusa.amoeba.mysql.net.MysqlClientConnectionFactory">
<property name="sendBufferSize">128</property>
<property name="receiveBufferSize">64</property>
</bean>
</property>
<property name="authenticator">
<bean class="com.meidusa.amoeba.mysql.server.MysqlClientAuthenticator">
<!-- amoeba对外连接数据库时的用户名 -->
<property name="user">root</property>
<!-- amoeba对外连接数据库时的密码 -->
<property name="password"></property>
<property name="filter">
<bean class="com.meidusa.amoeba.server.IPAccessController">
<property name="ipFile">${amoeba.home}/conf/access_list.conf</property>
</bean>
</property>
</bean>
</property>
</service>
<!-- server class must implements com.meidusa.amoeba.service.Service -->
<service name="Amoeba Monitor Server" class="com.meidusa.amoeba.monitor.MonitorServer">
<!-- port -->
<!-- default value: random number
<property name="port">9066</property>
-->
<!-- bind ipAddress -->
<property name="ipAddress">127.0.0.1</property>
<property name="daemon">true</property>
<property name="manager">${clientConnectioneManager}</property>
<property name="connectionFactory">
<bean class="com.meidusa.amoeba.monitor.net.MonitorClientConnectionFactory"></bean>
</property>
</service>
<runtime class="com.meidusa.amoeba.mysql.context.MysqlRuntimeContext">
<!-- proxy server net IO Read thread size -->
<property name="readThreadPoolSize">20</property>
<!-- proxy server client process thread size -->
<property name="clientSideThreadPoolSize">30</property>
<!-- mysql server data packet process thread size -->
<property name="serverSideThreadPoolSize">30</property>
<!-- per connection cache prepared statement size -->
<property name="statementCacheSize">500</property>
<!-- query timeout( default: 60 second , TimeUnit:second) -->
<property name="queryTimeout">60</property>
</runtime>
</proxy>
<!--
Each ConnectionManager will start as thread
manager responsible for the Connection IO read , Death Detection
-->
<connectionManagerList>
<connectionManager name="clientConnectioneManager" class="com.meidusa.amoeba.net.MultiConnectionManagerWrapper">
<property name="subManagerClassName">com.meidusa.amoeba.net.ConnectionManager</property>
<!--
default value is avaliable Processors
<property name="processors">5</property>
-->
</connectionManager>
<connectionManager name="defaultManager" class="com.meidusa.amoeba.net.MultiConnectionManagerWrapper">
<property name="subManagerClassName">com.meidusa.amoeba.net.AuthingableConnectionManager</property>
<!--
default value is avaliable Processors
<property name="processors">5</property>
-->
</connectionManager>
</connectionManagerList>
<!-- default using file loader -->
<dbServerLoader class="com.meidusa.amoeba.context.DBServerConfigFileLoader">
<property name="configFile">${amoeba.home}/conf/dbServers.xml</property>
</dbServerLoader>
<queryRouter class="com.meidusa.amoeba.mysql.parser.MysqlQueryRouter">
<property name="ruleLoader">
<bean class="com.meidusa.amoeba.route.TableRuleFileLoader">
<property name="ruleFile">${amoeba.home}/conf/rule.xml</property>
<property name="functionFile">${amoeba.home}/conf/ruleFunctionMap.xml</property>
</bean>
</property>
<property name="sqlFunctionFile">${amoeba.home}/conf/functionMap.xml</property>
<property name="LRUMapSize">1500</property>
<!--amoeba默认连接的server-->
<property name="defaultPool">master</property>
<!--允许在master上写数据-->
<!--
<property name="writePool">master</property>
<!--允许在MultiPool上读数据-->
<property name="readPool">MultiPool</property>
-->
<property name="needParse">true</property>
</queryRouter>
</amoeba:configuration>port: amoeba 服务器端口号
user: 登录amoeba的用户名
password: 登录amoeba的密码
defaultPool: 设置默认数据库节点,一般是 master 节点
writePool: 设置只读数据库节点
readPool: 设置只读数据库节点
启动:
sh /data/amoeba/bin/shutdown|start以上就是Amoeba一些简单的用法和配置,项目仅仅是用amoeba作数据库代理上(为了db安全考虑),没有用到主从和高可用。
主要参考文档: (资料实在是太少太不详尽了
https://www.jianshu.com/p/4aec9f682509
https://juejin.im/entry/596d71126fb9a06bbf70177c
http://wiki.hexnova.com/pages/viewpage.action?pageId=2031911
https://www.biaodianfu.com/amoeba.html
https://blog.51cto.com/tianshili/1640092