<?php
$NUM_OF_ATTEMPTS = 5;
$attempts = 0;
do {
try
{
executeCode();
} catch (Exception $e) {
$attempts++;
sleep(1);
continue;
}
break;
} while($attempts < $NUM_OF_ATTEMPTS);分类:php
php7 安装pg_sql, pdo_pgsql扩展
- 找到php源码包自带的ext目录里的pgsql库
- 切换目录到pgsql/pdo_pgsql
- 找到phpize(在php安装目录下的bin文件夹下)
- 如下命令:
# /usr/local/php/bin/phpize 为你的phpize安装目录
/usr/local/php/bin/phpize
# /usr/local/php/bin/php-config 为你的php-config安装目录
./configure --with-php-config=/usr/local/php/bin/php-config
make && make install- 配置扩展:
# /usr/local/php/etc/php.ini 为你的php.ini安装目录
extension=pgsql.so
extension=pdo_pgsql.so中间可能会遇到configure编译报错的情况:
configure: error: Cannot find libpq-fe.h. Please specify correct PostgreSQL installation path
解决方案:
yum -y install postgresql-develPHP PSR系列规范
PSR ( PHP Standard Recommendation的简写),它其实应该叫PSRs, 即系列推荐标准:目前通过的规范有PSR-0(Autoloading Standard), PSR-1(Basic Coding Standard), PSR-2(Coding Style Guide), PSR3(logger interface), PSR-4(Imporoved Autoloading)。它不是PHP官方标准,而是从Zend, Symfony2等知名PHP项目中提炼出来的一系列标准,目前有越来越多的社区项目加入成员并遵循该标准。
各个PSR规范的内容很简洁,大致如下:
PSR-0:
PSR-0即类自动加载规范(原文:官网、GitHub)。从2014-10-21日起,该规范被标记为Deprecated,由PSR-4替代。它的内容十分简洁。
- 一个完全合格的命名空间和类名必须有以下的结构“\<
Vendor Name>\(<Namespace>\)*<Class Name>” - 每个命名空间必须有顶级的命名空间(“Vendor Name”)
- 每个命名空间可以有任意多个子命名空间
- 每个命名空间在被从文件系统加载时必须被转换为“操作系统路径分隔符”(DIRECTORY_SEPARATOR )
- 每个“_”字符在“类名”中被转换为DIRECTORY_SEPARATOR 。“_”符号在命名空间中没有明确含义
- 符合命名标准的命名空间和类名必须以“.php”结尾来加载文件
Vendor Name,命名空间,类名可以由大小写字母组成,其中命名空间和类名是大小写敏感的以保证多系统兼容性
PSR-1:
PSR-1即基础编码标准(原文:官网、GitHub)。包含了类文件、类名、类方法名的命名方法。
- 源文件必须只使用 <?php 和 <?= 这两种标签
- 源文件中php代码的编码格式必须只使用不带BOM的UTF-8
- 一个源文件建议只用来做声明(类,函数,常量等)或者只用来做一些引起副作用的操作(例如:输出信息,修改.ini配置文件等),但不应该同时做这两件事
- 命名空间和类必须遵守PSR-0标准
- 类名使用StdudlyCaps写法( 大驼峰式 ,与caeCase区别在于,cameCase 是小驼峰,首字母小写)
- 类中的常量必须只由大写字母和下划线(_)组成
- 方法名必须使用cameCase写法
PSR-2:
它以PSR-1为基础,包含了缩进、每行代码长度、换行、方法可见性声明、空格和方法体大括号换行的相关规定
- 代码必须遵守 PSR-1
- 代码必须使用4个空格来进行缩进,而不是用制表符
- 一行代码的长度不应有硬限制;软限制必须为120个字符,建议每行代码80个字符或者更少
- 在命名空间的声明下面必须有一行空行,并且在use的声明下面也必须有一行空行
- 类的左花括号必须放到其声明下面自成一行,右花括号则必须放到类主体下面自成一行
- 方法的左花括号必须放到其声明下面自成一行,右花括号则必须放到方法主体的下一行
- 所有的属性和方法必须有可见性声明;abstract和final声明必须在可见性声明之前;而static声明必须在可见性声明之后
- 在结构控制关键字的后面必须有一个空格;而方法和函数调用时后面不可有空格
- 结构控制的左花括号必须跟其放在同一行,右花括号必须放在该结构控制代码主体的下一行
- 控制结构的左括号之后不可有空格,右括号之前也不可有空格
PSR-3:
PSR-3是对应用日志类的通过接口的定义(原文:官网、GitHub)。内容很简单,就是一个接口,官方示例代码引用一下就好了。当然,在具体的应用中,只要遵循该接口,肯定可以定制相应的实现。
- LoggerInterface暴露八个接口用来记录八个等级(debug, info, notice, warning, error, critical, alert, emergency)的日志
- 第9个方法是log,接受日志等级作为第一个参数。用一个日志等级常量来调用这个方法必须和直接调用指定等级方法的结果一致。用一个本规范中未定义且不为具 体实现所知的日志等级来调用该方法必须抛出一个Psr\Log\InvalidArgumentException。不推荐使用自定义的日志等级,除非你 非常确定当前类库对其有所支持
PSR-4:
PSR-4即改进版的自动加载规范,它是PSR-0规范的接替者。它可以与任何其它的自动加载规范兼容,包括PSR-0
- 术语「类」是一个泛称;它包含类,接口,traits 以及其他类似的结构
- 完全限定类名应该类似如下范例:<NamespaceName>(<SubNamespaceNames>)*<ClassName>
1. 完全合规类名必须有一个顶级命名空间(Vendor Name)
2. 完全合规类名可以有多个子命名空间
3. 完全合规类名应该有一个终止类名
4. 下划线在完全合规类名中是没有特殊含义的
5. 字母在完全合规类名中可以是任何大小写的组合
6. 所有类名必须以大小写敏感的方式引用
- 当从完全合规类名载入文件时
1.在完全合规类名中,连续的一个或几个子命名空间构成的命名空间前缀(不包括顶级命名空间的分隔符),至少对应着至少一个基础目录
2.在「命名空间前缀」后的连续子命名空间名称对应一个「基础目录」下的子目录,其中的命名 空间分隔符表示目录分隔符。子目录名称必须和子命名空间名大小写匹配
3. 终止类名对应一个以 .php 结尾的文件。文件名必须和终止类名大小写匹配
- 自动载入器的实现不可抛出任何异常,不可引发任何等级的错误;也不应返回值
PHP图片合成实践
最近有小朋友问我,电商网站上传listing 时,商品图片能否基于模板,把另一张商品图片通过程序的方式自动放到模板图片上,并且可以自动在合成的图片上某个位置写些商品介绍的文字,这样的话,就可以减少设计师或美工P图的工作量。以前大家常见的图片处理代码是利用gd库对图片进行缩放,比如上传一张图片的时候,顺带生成图片的缩略图或是在图片中打个水印等等,没有实现过图片合成这样的功能,所以花了点时间查了些资料自己实现了个简单的效果。
下面进入正题,如何实现两张图(一张模板,一张子图)的合并,并且往合成图片上写些文字,废话不多说,先上简易代码:
<?php
header('Content-type:image/jpeg; charset=utf-8');
if(!empty($_FILES)){
$remark = $_POST['remark'];
if (count($_FILES['demofile']['name']) == 2) {
$filename1 = $_FILES['demofile']['name'][0];
$filename2 = $_FILES['demofile']['name'][1];
$files1 = explode('.',$filename1);
$type1 = end($files1);
$time1 = date('YmdHis');
$head = '/tmp/';
$destination1 = $head.$time1.'_'.rand(100000, 999999).'.'.$type1;
//上传图片1
move_uploaded_file($_FILES['demofile']['tmp_name'][0], $destination1);
$files2 = explode('.',$filename2);
$type2 = end($files2);
$time2 = date('YmdHis');
$destination2 = $head.$time2.'_'.rand(100000, 999999).'.'.$type2;
//上传图片2
move_uploaded_file($_FILES['demofile']['tmp_name'][1], $destination2);
//background.jpg 背景图,程序的目的是将上传的图片放在背景图上
$imageDestination = './background.jpg'; //主视图,也就是白云飘飘这张主图
$imageDestination = imagecreatefromjpeg($imageDestination);
//创建图片资源句柄
$imageSource1 = imagecreatefromjpeg($destination1);
// $imageSource1 = $destination1; //复制并需旋转的小图
$imageSource2 = imagecreatefromjpeg($destination2);
//关键代码,将imageSource1图片合到imageDestination图片资源上
imagecopy($imageDestination, $imageSource1, 110, 150, 0, 0, imagesx($imageSource1), imagesy($imageSource1));
//将imageSource2图片合到imageDestination图片资源上
imagecopy($imageDestination, $imageSource2, 50, 595, 0, 0, imagesx($imageSource2), imagesy($imageSource2));
//合成完,如果要将图片另存,则利用imagejpeg的第二个参数实现
// imagejpeg($imageDestination, $head . "merge.jpg"); //输出图片
$black = imagecolorallocate($imageDestination, 65, 65, 65);
//关键代码,往imageDestination图片资源上写remark
imagettftext($imageDestination, 12, 0, 320, 190, $black,'/tmp/msyh.ttf', $remark);
imagejpeg($imageDestination);
} else {
echo "你没有上传两张图片";
}以上代码的作用是上传两张图片,将上传的图片放到background.jpg 这张背景图的指定位置上,并且往background背景指定位置上写上说明文字,就这么简单,当然上述代码很粗糙,没有兼容不同的图片格式,没有判断图片大小,没有对图片的比例判断,如果大于某个比例,没有缩放,没有考虑说明文字的长度,会不会长了自动折行等等,我们在这里只是讲个大概的原理,细节需要自行去完善。
代码关键回顾,核心方法如下,主要利用了imagecopy(将src_im copy到dst_im上),imagejpeg(从image图像创建jpeg图像),imagettftext(将文字写入image中)这三个方法:
- imagecopy ( resource
$dst_im, resource$src_im, int$dst_x, int$dst_y, int$src_x, int$src_y, int$src_w, int$src_h) 方法: 将src_im图像中坐标从src_x,src_y开始,宽度为src_w,高度为src_h的一部分拷贝到dst_im图像中坐标为dst_x和dst_y的位置上 - imagejpeg ( resource
$image[, string$filename[, int$quality]] ):从image图像以filename为文件名创建一个 JPEG 图像 - imagettftext ( resource
$image, float$size, float$angle, int$x, int$y, int$color, string$fontfile, string$text) : 使用 TrueType 字体将 指定的text写入图像。
当然,这种合成后的效果,取决于原始图片和模板之间的色差及融入度。所以图片和模板的颜色要一致,程序只是简单将A放到B的某个位置上,而无法智能的像设计师或美工一样P图,否则设计师就失业了。
php自定义扩展开发
文章源于: https://www.bo56.com/php7%E6%89%A9%E5%B1%95%E5%BC%80%E5%8F%91%E4%B9%8Bhello-word/ ,经亲自验证,此文章代码只适用于php7
我们来生成一个say扩展,say扩展提供say方法,方法功能是返回hello world字符串
- 利用ext_skel 生成扩展骨架
cd /data/src/php-7.2.25/ext //进入php源码扩展目录
./ext_skel --extname=sayextname参数的值就是扩展名称。执行ext_skel命令后,这样在当前目录下会生成一个与扩展名一样的目录。
- 修改config.m4配置文件
config.m4的作用就是配合phpize工具生成configure文件。configure文件是用于环境检测的。检测扩展编译运行所需的环境是否满足。现在我们开始修改config.m4文件。
$ cd ./say
$ vim ./config.m4dnl If your extension references something external, use with:
dnl PHP_ARG_WITH(say, for say support,
dnl Make sure that the comment is aligned:
dnl [ --with-say Include say support])
dnl Otherwise use enable:
dnl PHP_ARG_ENABLE(say, whether to enable say support,
dnl Make sure that the comment is aligned:
dnl [ --enable-say Enable say support])其中,dnl 是注释符号。上面的代码说,如果你所编写的扩展如果依赖其它的扩展或者lib库,需要去掉PHP_ARG_WITH相关代码的注释。否则,去掉 PHP_ARG_ENABLE 相关代码段的注释。我们编写的扩展不需要依赖其他的扩展和lib库。因此,我们去掉PHP_ARG_ENABLE前面的注释。去掉注释后的代码如下:
dnl If your extension references something external, use with:
dnl PHP_ARG_WITH(say, for say support,
dnl Make sure that the comment is aligned:
dnl [ --with-say Include say support])
dnl Otherwise use enable:
PHP_ARG_ENABLE(say, whether to enable say support,
Make sure that the comment is aligned:
[ --enable-say Enable say support])- 代码实现
修改say.c文件。实现say方法。
找到PHP_FUNCTION(confirm_say_compiled),在其上面增加如下代码:
PHP_FUNCTION(say)
{
zend_string *strg;
strg = strpprintf(0, "hello word");
RETURN_STR(strg);
}找到 PHP_FE(confirm_say_compiled, 在上面增加如下代码:
PHP_FE(say, NULL)修改后的代码如下:
const zend_function_entry say_functions[] = {
PHP_FE(say, NULL) /* For testing, remove later. */
PHP_FE(confirm_say_compiled, NULL) /* For testing, remove later. */
PHP_FE_END /* Must be the last line in say_functions[] */
};- 编译安装
/usr/local/php-7.2.25/bin/phpize
./configure --with-php-config=/usr/local/php-7.2.25/bin/php-config
make
make install
//进入扩展目录
-rwxr-xr-x 1 root root 151K Apr 14 11:32 mcrypt.so
-rwxr-xr-x 1 root root 3.5M Apr 14 11:21 opcache.a
-rwxr-xr-x 1 root root 1.9M Apr 14 11:21 opcache.so
-rwxr-xr-x 1 root root 104K Apr 14 11:28 pcntl.so
-rwxr-xr-x 1 root root 1.7M Apr 14 12:05 redis.so
-rwxr-xr-x 1 root root 31K May 31 10:14 say.so //自定义的扩展- 编辑php.ini文件
extension="say.so"- 命令行测试扩展
[root@ip /usr/local/php/lib]# /usr/local/php/bin/php -r "echo say();"
hello word[root@ip /usr/local/php/lib]# job告警定位全过程
最近两天领了一个活,定位项目中一个job的告警原因。
任务背景:这个job是每晚定时运行,job大体功能是多进程分片(最大同时有8个进程)去循环连接各个分库(库的数量数以万计),进入分库后,再进行两层循环的计算(总共三层循环),此job运行五分钟之后,总会时不时报,找不到分库数据源(但是实际上去db中查找,有些是脏的分库真不存在,但是有的数据源确实真存在)
定位方法&过程:
- 既然告警当中确有不存在的数据源,会不会是其中一个分片进程循环遇到找不到的数据源而引起后面的连接出错的连锁反应呢?
于是决定写一个脚本,把所有确不存在的脏数据源给理出来,然后统一在外层过滤掉,使得每个分片逻辑中不会去连脏的数据源 - 当我完成上一步清理掉脏数据源后,再次跑了下这个job, 这次依旧是跑了五分钟后抛出几百封告警邮件,随机抽查了下,这次告警连不上的数据源都是存在的
那么问题出在哪呢?只能详细去查代码定位了 🙁
<?php
//伪代码如下
...
//如果缓存数据源池里存在此数据源名,则直接从中取
if ($name存在于缓存的连接池中) {
$conn = 缓存连接池里取出传入的连接名的数据库配置;
} elseif (属于指定环境) {
$conn = 重新从数据源配置表里读取配置($name);
} else {
$conn = null;
}
if (empty($conn)) {
抛异常("数据源名:" . $name...);
....
}
...
?>根据报错,是走进了empty conn逻辑,然后抛异常出来。那么问题来了,上面有if, elseif, else三个分支逻辑,究竟走到哪个分支逻辑,使得conn为空呢,目测的话,有可能走进elseif ,也有可能是走过了else逻辑,为了先确认这个问题,我把代码改了一下:
<?php
//伪代码如下
...
//如果缓存数据源池里存在此数据源名,则直接从中取
if ($name存在于缓存的连接池中) {
$flag = 1;
$conn = 缓存连接池里取出传入的连接名的数据库配置;
} elseif (属于指定环境) {
$flag = 2;
$conn = 重新从数据源配置表里读取配置($name);
} else {
$flag = 3;
$conn = null;
}
if (empty($conn)) {
//之所以在这里重定向,而不在上面分支逻辑中埋log, 是因为上面的逻辑if elseif是正常逻辑,所有的正常业务,也可能会走到,会产生不必要的log
error_log("empty conn, flag:" . $flag, 3, "/tmp/empty_conn.log");
抛异常("数据源名:" . $name...);
....
}
...
?>按照上面的代码,就知道走哪个分支逻辑使得conn变量为空了,这样便可以进一步知道null的来源,结论:定位到是else逻辑“$conn = 重新从数据源配置表里读取配置($name);”导致conn为空的。
紧接着查看“ 重新从数据源配置表里读取配置 ”这个方法,此方法主要是根据name传参查出数据源。
在此方法中再次埋了下log, 在mysqli_connect连接后打印了mysqli_errorno和mysqli_error()
mysqli_error()返回的信息是: “Cannot assign requested address“,其实这里面埋log 也一波三折,具体过程就不细聊了。
下面来看一下”Cannot assgin requested address”的原因分析:
“Cannot assign requested address.”是由于linux分配的客户端连接端口用尽,无法建立socket连接所致,虽然socket正常关闭,但是端口不是立即释放,而是处于TIME_WAIT状态,默认等待60s后才释放。为什么会用尽呢?通常这个情况出现在高并发数据库又是短连接,端口迅速被分配完,虽然代码层有mysql close 但是端口并不会快速被释放,所以就出现了此问题。
如何解决, 网上查了下解决方案:
解决方法1–调低time_wait状态端口等待时间:
- 调低端口释放后的等待时间,默认为60s,修改为15~30s
sysctl -w net.ipv4.tcp_fin_timeout=30 - 修改tcp/ip协议配置, 通过配置/proc/sys/net/ipv4/tcp_tw_resue, 默认为0,修改为1,释放TIME_WAIT端口给新连接使用
sysctl -w net.ipv4.tcp_timestamps=1 - 修改tcp/ip协议配置,快速回收socket资源,默认为0,修改为1
sysctl -w net.ipv4.tcp_tw_recycle=1
解决办法2–增加可用端口:
shell> $ sysctl -a | grep port_range
net.ipv4.ip_local_port_range = 50000 65000 -----意味着50000~65000端口可用 修改参数:
$ vi /etc/sysctl.conf
net.ipv4.ip_local_port_range = 10000 65000 -----意味着10000~65000端口可用改完后,执行命令“sysctl -p”使参数生效,不需要reboot
但是我没有按照上面的方案来优化,原因主要是:
我再次跑了下此job, 告警的时候,我观察了下netstat -an | grep TIME_WAIT | wc -l, 结果一度飙到6w多,所以爆了,job一度告警,不仅这个job, 其他同时间的job也受到牵连,根据经验,闲时的并发量,一般达不到这个值。代码应该写的有些许问题。但是目前不想去改代码,因为改代码:一,需要时间;二,需要验证。
我做了如下几点优化:
- 查数据库源配置信息的方法,之前每次循环查一次就连一次db,我将连db这里做成了单例,第二次循环之后,用的是前一次连接句柄。 接着观察了下db的tcp连接数,已经较之前下降了一半, 但是按照上面的修改,仍然不能满足要求,试了下单纯只跑这个job 虽然不会告警,但是如果同一时间有其他job也在跑的话,很可能还会告警,TIME_WAIT仍然会很高。
- 降低此job总的并发进程数
- 限制此job在每台job机上的运行个数
通过上面三个优化手段之后,再次跑了下此job,并且是模拟正常job量的情况下运行的,发现已经没有告警了。当然后续可以对此脚本再优化,也是能起到一定效果的。
再次查资料查了下TIME_WAIT相关资料:
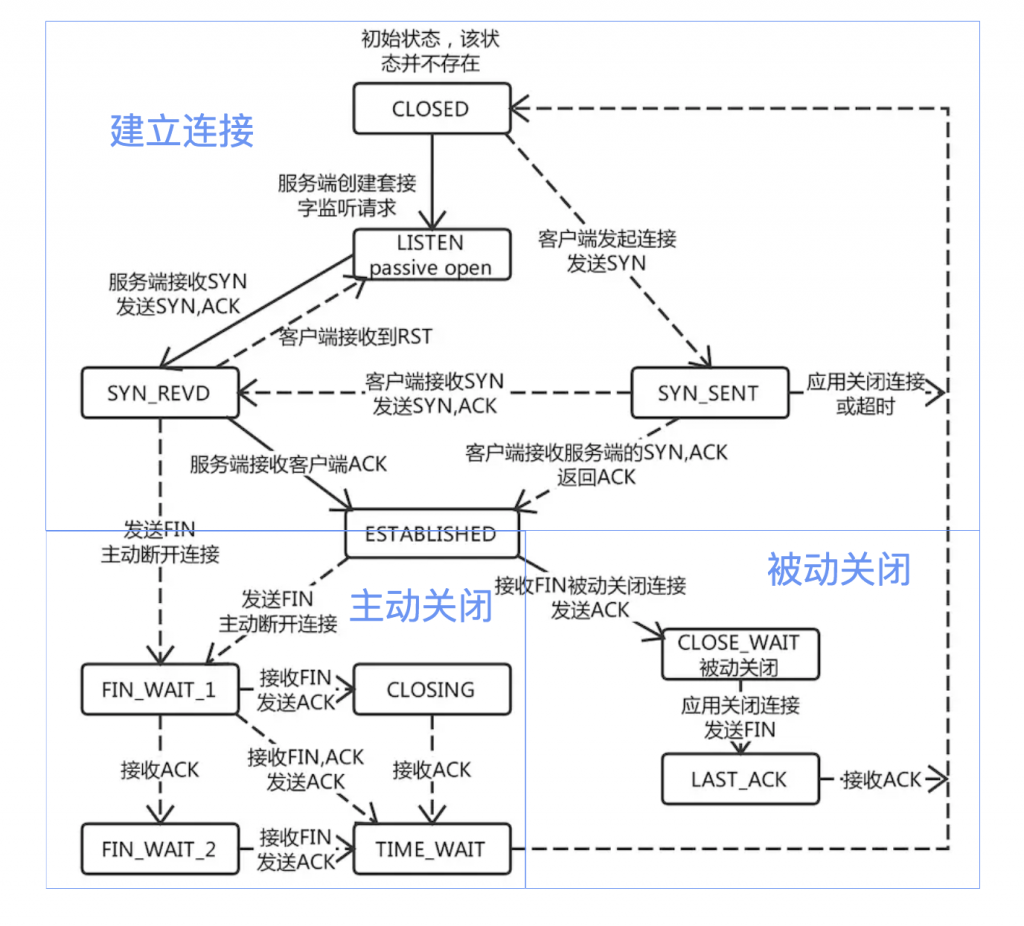
一眼看过去,这么多状态,各个方向的连线,但是整个图可以被划分为三个部分,上半部是建立连接的过程,左下部是主动关闭连接,右下部是被动关闭连接的过程。
从上图可以看出来,当TCP连接主动关闭时,会经过TIME_WAIT状态,所以TIME_WAIT状态是TCP四次握手结束后,连接双方都不再交换消息,但主动关闭的一方保持这个连接一段时间内不可用。
那这个TIME_WAIT状态有什么用呢?
暂以 A、B 来代指 TCP 连接的两端,A 为主动关闭的一端。
四次挥手中,A 发 FIN, B 响应 ACK,B 再发 FIN,A 响应 ACK 实现连接的关闭。而如果 A 响应的 ACK 包丢失,B 会以为 A 没有收到自己的关闭请求,然后会重试向 A 再发 FIN 包。
如果没有 TIME_WAIT 状态,A 不再保存这个连接的信息,收到一个不存在的连接的包,A 会响应 RST 包,导致 B 端异常响应。
此时, TIME_WAIT 是为了保证全双工的 TCP 连接正常终止。
允许老的重复分节在网络中消逝:
我们还知道,TCP 下的 IP 层协议是无法保证包传输的先后顺序的。如果双方挥手之后,一个网络四元组(src/dst ip/port)被回收,而此时网络中还有一个迟到的数据包没有被 B 接收,A 应用程序又立刻使用了同样的四元组再创建了一个新的连接后,这个迟到的数据包才到达 B,那么这个数据包就会让 B 以为是 A 刚发过来的。
此时, TIME_WAIT 的存在是为了保证网络中迷失的数据包正常过期。
那TIME_WAIT的时长是多少呢?
TIME_WAIT的过期时间,MSL(最大分段寿命,Maximum Segment Lifetime),它表示一个TCP分段可以存在于互联网系统中的最大时间,由TCP的实现,超出这个寿命的分片就会被丢弃。
TIME_WAIT 状态由主动关闭的 A 来保持,那么我们来考虑对于 A 来说,可能接到上一个连接的数据包的最大时长:A 刚发出的数据包,能保持 MSL 时长的寿命,它到了 B 端后,B 端由于关闭连接了,会响应 RST 包,这个 RST 包最长也会在 MSL 时长后到达 A,那么 A 端只要保持 TIME_WAIT 到达 2MSL 就能保证网络中这个连接的包都会消失。
MSL 的时长被 RFC 定义为 2分钟,但在不同的 unix 实现上,这个值不并确定,我们常用的 centOS 上,它被定义为 30s,我们可以通过 /proc/sys/net/ipv4/tcp_fin_timeout 这个文件查看和修改这个值。2MSL就是60s.
大量TIME_WAIT造成的影响:
在高并发短连接的TCP服务器上,当服务器处理完请求后立刻主动正常关闭连接。这个场景下会出现大量socket处于TIME_WAIT状态。如果客户端的并发量持续很高,此时部分客户端就会显示连接不上。
主动正常关闭TCP连接,都会出现TIMEWAIT。
为什么我们要关注这个高并发短连接呢?有两个方面需要注意:
- 高并发可以让服务器在短时间范围内同时占用大量端口,而端口有个0~65535的范围,并不是很多,刨除系统和其他服务要用的,剩下的就更少了。
- 在这个场景中,短连接表示”业务处理+传输数据的时间 远远小于 TIMEWAIT超时的时间”的连接。
这里有个相对长短的概念,比如取一个web页面,1秒钟的http短连接处理完业务,在关闭连接之后,这个业务用过的端口会停留在TIMEWAIT状态几分钟,而这几分钟,其他HTTP请求来临的时候是无法占用此端口。
PHP性能优化实战
背景
最近在做平台的性能优化,源于前一段时间平台的性能掉的很严重,后台页面的平均响应时间一度掉到500ms左右
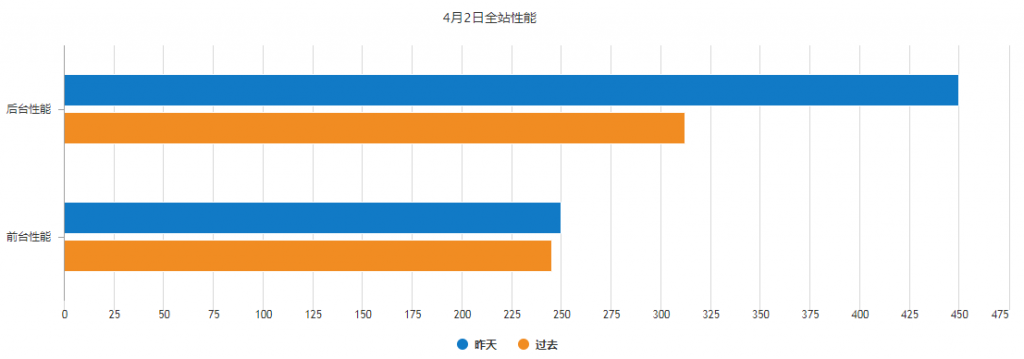
变差前正常的性能(320ms左右):
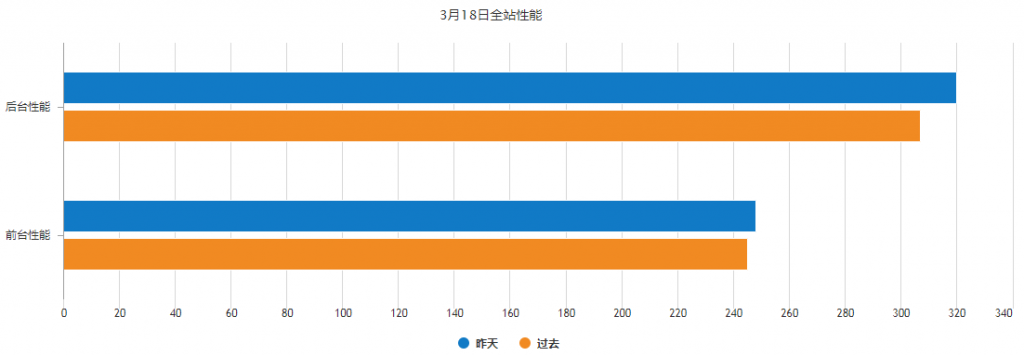
4.1号的性能邮件,展示的是3.31号平台性能,而3.30号是迭代发布之日,所以断定在3.30发布之后(之前的一个迭代开发中),引入了低效代码,导致性能下降
然而,最近平台在升级php7,在4.17号php7升级之后,平台的性能如下:
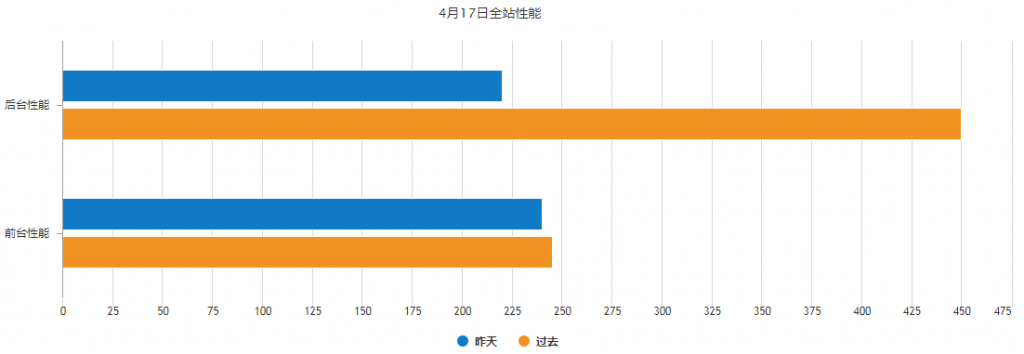
由此可以看到,php7升级,让平台后端性能从450ms提升到210ms,平台性能提升了50%+。
那么问题来了,假设我们是从原来正常的性能(320ms)提升的话,或许效果会更好,于是开始了我们这篇文章的正文,这篇文章记录的是我试图找回之前迭代开发损失的性能的一些方法。
安装性能定位工具
工欲善其事,必先利其器,安装xhprof php profiler工具,具体安装方法见:
https://juejin.im/post/5a1d507751882531ba10b0e9
之前平台升php5.6.36之后,用的是tideways扩展(不能直观的查看页面的性能),前些年当时xhprof还不支持php这个版本, 但是目前按上面文章的方法安装,我试了下,已经可以支持到php7版本,可以直接页面点击链接查看当前页面的性能
我修改了下平台框架入口代码:
$xhprof_on = false;
//for xhprof starting----
if(extension_loaded('xhprof') && defined('xhprof_enable') && xhprof_enable == 1) {
xhprof_enable(XHPROF_FLAGS_CPU + XHPROF_FLAGS_MEMORY);
$xhprof_on = true;
}
if($xhprof_on){
$xhprof_data = xhprof_disable();
$xhprof_root = '/data/www/xhprof_db/';
include_once $xhprof_root."xhprof_lib/config.php";
include_once $xhprof_root."xhprof_lib/utils/xhprof_lib.php";
include_once $xhprof_root."xhprof_lib/utils/xhprof_runs.php";
$xhprof_runs = new XHProfRuns_Default();
$run_id = $xhprof_runs->save_run($xhprof_data, "hx");
if(体验环境) {
echo '<a href="http://xhprof.oa.com/index.php?run='.$run_id.'&source=hx" target="_blank">xhprof</a>';
}
}
同时nginx 配置要支持xhprof.oa.com这个域名:
server {
listen 80;
root /data/www/xhprof/xhprof_html/;
server_name xhprof.oa.com;
location = / {
index index.php;
}
location ~ \.php {
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
}
最终的效果:
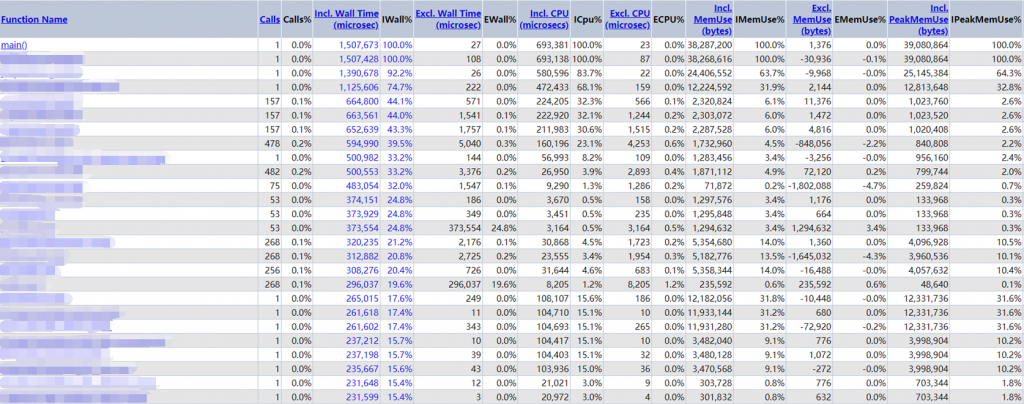
xhprof profiler图展示的是当前页面,从框架入口开始,页面各个方法的调用次数和执行时间,具体字段含义可以看上面安装链接中的介绍,这里我主要关注calls(方法调用次数),Incl.Wall Time( 方法执行花费的时间,包括子方法的执行时间 ),IWall%(花费时间占比)这三个字段。Incl.Wall Time值大的,IWall% 占比大的,就是当前页面比较耗时的方法。calls多的,表示方法次数比较多(可能是因为此方法置于循环内)。
在介绍具体优化代码之前,先介绍下我的思路:
起初我想从3.16~3.26这段时间内的迭代变更的文件里去试图查找性能差的代码,但是实操起来,我放弃了,这段时间内提交的代码次数太多,代码量也比较大,一个个看,两个规模点的需求,基本上很难在一两天内完成任务。
于是我换了个思路,优化访问量大的页面和框架入口基类beforeFilter方法(基本所有页面都会执行到这个方法),这样有利于削平平均值。
于是我从点击流(一个用户画像操作记录的表)中统计了下性能变差时间段内访问量大,且group by后台响应时间平均值大的页面
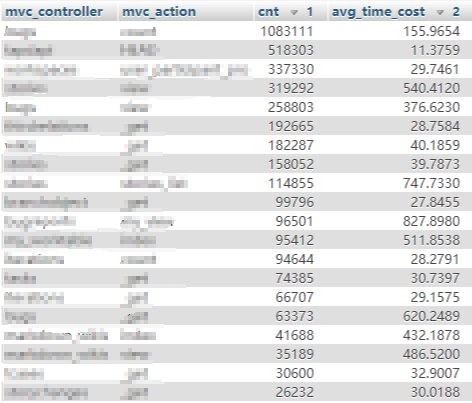
PS:如果没有这样一张表, 要得到哪个请求访问量大, 其实也很简单, 可以通过nginx access log 加上shell 命令, 也是可以统计出来的,方法总比问题多.
有了上面页面的访问量+时长排序,再加上xhprof 工具,感觉就成功了一半了,接下来就是对具体页面的代码优化。
以下是我优化的一些代码片断
/**
foreach里减少数据库查询IO,减少 IO 次数
IO永远是数据库最容易瓶颈的地方,这是由数据库的职责所决定的,大部分数据库操作中超过90%的时间都是 IO 操作所占用的,减少 IO 次数是 SQL 优化中需要第一优先考虑,当然,也是收效最明显的优化手段。
*/
-foreach ($app_ids as $app_id) {
- if (查数据库是否启用($app_id)) {
- $match_app_ids[] = $app_id;
- }
-}
+$match_app_ids = 批量查一批id是否满足($app_ids)
//大体就是用一条sql 去获取满足要求的app id/**
缓存没用上,而且这个方法是beforefilter里每个请求都会调用到的
*/
$cache_key = ("xxxxxx").$user_id;
$cache_data = $cache->get($cache_key);
-if (true || empty($cache_data)) {
+if (empty($cache_data)) {
...../**
实例化类多次,单例不需要实例化多次,用一个变量存储先
*/
-g('aaaa')->xxxx($this);
+$aaaa = g('aaaa');
+$aaaa->xxxx($this);
……
+$aaaa->yyyy();
-g('aaaa')->yyyy();/**
每个请求都会读取的配置,利用缓存存储,只读一次db
利用缓存降低db读取
*/
public function test($user='') {
………
-return !empty($config->find(['type'=>'xxxconfig','name'=>$user]));
+$cache_key = "config_list";
+$config_list = Cache::get($cache_key);
+if (empty($config_list) || !is_array($config_list)) {
+ $config_rules = $config->findAll(['type'=>'xxxconfig']);
+ $config_list = array();
+ foreach ($config_rules as $key => $config_rule) {
+ $config_list[] = $config['Setting']['name'];
+ }
+ Cache::add($cache_key, $config_list, '+1 year');
+}
return in_array($user, $config_list);
}/**
一个方法类,同一个变量值,反复计算,只计算一次
*/
+$x = $a->b($z);
-if ($a->b($z)) {
+if ($x) {
.....
-if ($a->b($z)) {
+if ($x) {
}/**
foreach循环里多次计算,其实没必要,虽然耗时不长,但是调用了几十次,也增加了一定开销
*/
foreach($as as $a){
-$a=$a[g('A')->name];
+$a=$a['A'];
$a_data[$a['id']]=$a;
}以上只是举了几个优化的例子,其实这次优化的地方有很多, 下面提炼下一些优化方法
- 减少数据库io(这个效果很不错,循环次数越多,性能就越明显)
- 同一个计算值在方法内多次复制粘贴,可以用一个变量存储,计算一次
- 实例化多次,用变量存储一次,如果实例化与状态无关的话
- 数据库查询语句要注意是否使用到索引(这个效果很明显,这次优化有张表没加索引,加上后,性能杠杠的)
- 判断元素是否在数组中, 如果数组比较大的话 , isset比in_array效率高
- 合理使用内存,及时unset掉或是释放掉内存或文件/数据库句柄
- 少用正则表达式,正则用起来爽,但是效率很低,越复杂的正则效率越低
- 如果能将类的方法定义成static,就尽量定义成static,它的速度会提升将近4倍
- row[‘id’]的性能是row[id]的七倍
- 尽量避免使用__get,__set,__autoload
- include文件时尽量使用绝对路径,因为避免了PHP去include_path里查找文件的速度,解析操作系统路径所需的时间会更少
- 尽量做缓存,可使用redis, memcached。缓存可用来加速动态Web应用程序,减轻数据库负载。对运算码 (OP code)的缓存很有用,使得脚本不必为每个请求做重新编译
- 当执行变量的递增或递减时,i++会比++i慢一些。这种差异是特有的,并不适用于其他语言
- 尽量采用大量的PHP内置函数
- foreach效率更高,尽量用foreach代替while和for循环
- 用单引号替代双引号引用字符串 (双引号要解析判断有无变量)
- 对global变量,应该用完就unset()掉
- 如果在代码中存在大量耗时的函数,你可以考虑用C扩展的方式实现它们
- 尽量少进行文件操作,虽然PHP的文件操作效率也不低
期待优化后的代码上线,希望能降到200ms 以下, 提升20ms的性能(10%的提升)。别看只有20ms,当平台性能达到一定阶段后,几毫秒都是难以优化的。提升机器配置和换语言除外
优化后的效果(未来随着不断优化会越来越好):

其实上面聊的都是些代码层的优化方案,除此之外,其实优化可以做很多,早些年,Yahoo出了个36条,里面很大一部分是前端优化的一些方案,优化可以分为后端优化,前端优化,组件优化,服务器优化等等,再整体聊聊整体的性能优化方案
- 前端
1.减少http请求,比如常见的用sprite图,现在构建工具很多都能自动生成,比起早些年,已经方便太多
2.css, js压缩合并,减小文件体积,加快网络传输
3.前端缓存
4.css置于前面,防止页面重绘
5.不使用css表达式
6.让ajax可以缓存
7.减少dom数量
8.懒加载
9.减少cookie大小
10.cdn
- 后端
除了上面那些之外,还有:
1.页面静态化(全局或局部静态化)
2.服务器gzip压缩等等
- 服务器优化
1.提升配置
2.优化参数,比如tcp连接端口数,timewait释放时间等
CORS详解
文章来源: http://www.ruanyifeng.com/blog/2016/04/cors.html
之所以查cors,原因是今天发现我之前做的docker,在发布之后,竟然有个跨域问题

之前都可用,但是今天突然不可用了,想到之前遇到跨域问题,也有通过add header “Access-Control-Allow-Origin” 解决过,但是没有详细了解这块内容,只是为了解决问题临时查资料码代码,经过一番定位后,结果发现我的跨域问题并非没有吐cors响应头引起的,而是后端有报错。但是network里却没有显示出来。error_log 里却可以看到是有报错,用curl -v 查看http请求详情发现返回的httpcode 是500(Server Internal 500),导致响应头没有吐回,从而导致console显示跨域。不过当时误以为是响应头设置问题,仔细查了下这块的资料,特此手打记录一下:
cors是一个W3C标准,全称“跨域资源共享”(Cross-origin resource sharing)
它允许浏览器向跨源服务器,发出xhr请求,从而克服ajax只能同源使用的限制。
CORS机制:
cors需要浏览器和服务器同时支持。目前,所有浏览器都支持该功能,IE浏览器不能低于IE10
整个cors通信过程,都是浏览器自动完成,不需要用户参与,对于开发者来说,cors通信与同源的ajax通信没有差别,代码完全一样。浏览器一旦发现ajax请求跨源,就会自动添加一些附加的头信息,有时还会多出一次附加请求,但用户不会有感觉。
因此,实现cors通信的关键是服务器,只要服务器实现了cors接口,就可以跨源通信。
浏览器将cors请求分为两类,一类是简单请求,另一类是非简单请求,只要同时满足以下两大条件,就属于简单请求:
- 请求方法是以下三种方法之一:HEAD、GET、POST
- HTTP头信息不超过以下几种字段
a.Accept
b.Accept-Language
c.Content-Language
d.Last-Event-ID
e.Content-Type: 只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain
凡是不同时满足以上两个条件,就属于非简单请求。
- 简单请求的基本流程:
对于简单请求,浏览器直接发出cors请求,具体来说,就是在头信息中,增加一个Origin字段。
下面是一个例子,浏览器发现这次跨源xhr请求是简单请求,就自动在头信息之中,添加一个Origin字段。
GET /cors HTTP/1.1
Origin: http://api.bob.com
Host: api.alice.com
Accept-Language: en-US
Connection: keep-alive
User-Agent: Mozilla/5.0...上面的头信息中,Origin字段用来说明,本次请求来自哪个源(协议+域名+端口)。服务器根据这个值,决定是否同意这次请求。
如果Origin指定的源,不在许可范围内,服务器会返回一个正常的HTTP回应。浏览器发现,这个回应的头信息里没有包含Access-Control-Allow-Origin字段,就知道出错了,从而抛出一个错误,被xhr的onerror回调函数捕获。ps: 这种错误无法通过状态码识别,因为http code有可能是200。
如果Origin指定的域名在许可范围内,服务器返回的响应,会多出几个头信息字段。
Access-Control-Allow-Origin: http://api.bob.com
Access-Control-Allow-Credentials: true
Access-Control-Expose-Headers: FooBar
Content-Type: text/html; charset=utf-8上面的头信息之中,有三个与cors请求相关的字段,都以Access-Control-开头。
- Access-Control-Allow-Origin
该字段是必须的,它的值要么是请求时Orgin字段的值,要么是一个*,表示接受任意域名的请求。
- Access-Control-Allow-Credentials
该字段可选,它的值是一个布尔值,表示是否允许发送Cookie, 默认情况下,Cookie不包括在cors请求中,设为true, 即表示服务器明确许可,Cookie可以包含在请示中,一起发给服务器。这个值也只能设为true, 如果服务器不再浏览器发送Cookie, 删除该字段即可。
- Access-Control-Expose-Headers
该字段可选。CORS请求时,XMLHttpRequest对象的getResponseHeader()方法只能拿到6个基本字段:Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma。如果想拿到其他字段,就必须在Access-Control-Expose-Headers里面指定。上面的例子指定,getResponseHeader(‘FooBar’)可以返回FooBar字段的值。
- withCredentials 属性
上面说到,cors请求默认不发送Cookie和http认证信息。如果要把Cookie发到服务器,一方面要服务器同意,指定Access-Control-Allow-Credentials字段
Access-Control-Allow-Credentials: true另一方面,开发者必须在ajax请求中打开withCredentials属性
var xhr = new XMLHttpRequest();
xhr.withCredentials = true;否则,即使服务器同意发送Cookie, 浏览器也不会发送。或者,服务器要求设置Cookie, 浏览器也不会处理。
但是,如果省略withCredentials设置,有的浏览器还是会一起发送Cookie。这时,可以显示关闭withCredentials。
xhr.withCredentials = false;需要注意的是,如果要发送Cookie, Access-Control-Allow-Origin就不能设为*, 必须指定明确的,与请求网页一致的域名。同时,Cookie依然遵循同源政策,只有用服务器域名设置的Cookie才会上传,其他域名的Cookie并不会上传,且(跨源)原网页代码中的document.cookie也无法读取服务器名下的cookie。
- 非简单请求
预检请求
非简单请求是那种对服务器有特殊要求的请求,比如请求方法是PUT或DELETE,或者Content-Type字段的类型是application/json。
非简单请求的CORS请求,会在正式通信之前,增加一次HTTP查询请求,称为”预检”请求(preflight)。
浏览器先询问服务器,当前网页所在的域名是否在服务器的许可名单之中,以及可以使用哪些HTTP动词和头信息字段。只有得到肯定答复,浏览器才会发出正式的XMLHttpRequest请求,否则就报错。
下面是一段浏览器的JavaScript脚本。
var url = 'http://api.alice.com/cors';
var xhr = new XMLHttpRequest();
xhr.open('PUT', url, true);
xhr.setRequestHeader('X-Custom-Header', 'value');
xhr.send();上面代码中,HTTP请求的方法是PUT,并且发送一个自定义头信息X-Custom-Header。
浏览器发现,这是一个非简单请求,就自动发出一个”预检”请求,要求服务器确认可以这样请求。下面是这个”预检”请求的HTTP头信息。
OPTIONS /cors HTTP/1.1
Origin: http://api.bob.com
Access-Control-Request-Method: PUT
Access-Control-Request-Headers: X-Custom-Header
Host: api.alice.com
Accept-Language: en-US
Connection: keep-alive
User-Agent: Mozilla/5.0...“预检”请求用的请求方法是OPTIONS,表示这个请求是用来询问的。头信息里面,关键字段是Origin,表示请求来自哪个源。
除了Origin字段,”预检”请求的头信息包括两个特殊字段。
(1)Access-Control-Request-Method
该字段是必须的,用来列出浏览器的CORS请求会用到哪些HTTP方法,上例是PUT。
(2)Access-Control-Request-Headers
该字段是一个逗号分隔的字符串,指定浏览器CORS请求会额外发送的头信息字段,上例是X-Custom-Header。
预检请求回应
服务器收到”预检”请求以后,检查了Origin、Access-Control-Request-Method和Access-Control-Request-Headers字段以后,确认允许跨源请求,就可以做出回应。
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 01:15:39 GMT
Server: Apache/2.0.61 (Unix)
Access-Control-Allow-Origin: http://api.bob.com
Access-Control-Allow-Methods: GET, POST, PUT
Access-Control-Allow-Headers: X-Custom-Header
Content-Type: text/html; charset=utf-8
Content-Encoding: gzip
Content-Length: 0
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Content-Type: text/plain上面的HTTP回应中,关键的是Access-Control-Allow-Origin字段,表示http://api.bob.com可以请求数据。该字段也可以设为星号,表示同意任意跨源请求。
如果浏览器否定了”预检”请求,会返回一个正常的HTTP回应,但是没有任何CORS相关的头信息字段。这时,浏览器就会认定,服务器不同意预检请求,因此触发一个错误,被XMLHttpRequest对象的onerror回调函数捕获。控制台会打印出如下的报错信息。
XMLHttpRequest cannot load http://api.alice.com.
Origin http://api.bob.com is not allowed by Access-Control-Allow-Origin.服务器回应的其他cors相头字段:
Access-Control-Allow-Methods: GET, POST, PUT
Access-Control-Allow-Headers: X-Custom-Header
Access-Control-Allow-Credentials: true
Access-Control-Max-Age: 1728000(1)Access-Control-Allow-Methods
该字段必需,它的值是逗号分隔的一个字符串,表明服务器支持的所有跨域请求的方法。注意,返回的是所有支持的方法,而不单是浏览器请求的那个方法。这是为了避免多次”预检”请求。
(2)Access-Control-Allow-Headers
如果浏览器请求包括Access-Control-Request-Headers字段,则Access-Control-Allow-Headers字段是必需的。它也是一个逗号分隔的字符串,表明服务器支持的所有头信息字段,不限于浏览器在”预检”中请求的字段。
(3)Access-Control-Allow-Credentials
该字段与简单请求时的含义相同。
(4)Access-Control-Max-Age
该字段可选,用来指定本次预检请求的有效期,单位为秒。上面结果中,有效期是20天(1728000秒),即允许缓存该条回应1728000秒(即20天),在此期间,不用发出另一条预检请求。
php7 升级之mongodb扩展
mongo扩展(mongo.so)是一个比较老的扩展,主要用于php5, 建议php5.4之后,使用mongodb扩展,php7已经不支持mongo扩展。( https://www.php.net/manual/zh/mongo.installation.php )
下载地址: https://pecl.php.net/package/mongo
mongo使用说明: https://www.php.net/manual/zh/book.mongo.php
mongodb扩展mongodb.so是目前官方维护的版本,可以直接使用该驱动,但是官方建议和phplib一起使用,phplib封装了一个功能更全面的API.
下载地址: https://pecl.php.net/package/mongodb
PHPLIB地址: https://github.com/mongodb/mongo-php-library
使用方法: http://php.net/manual/en/set.mongodb.php

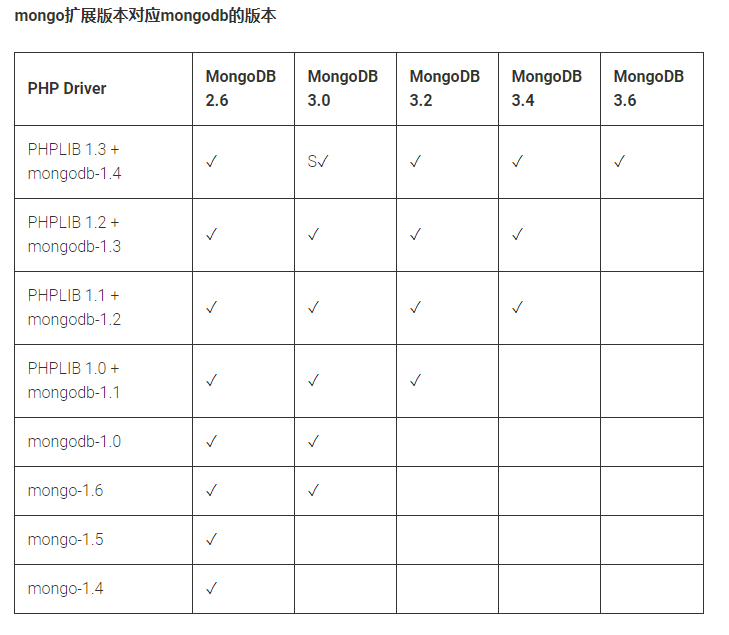
升级注意事项:
mongodb只有长连接
mongo扩展只有close()方法,为了避免出现长连接数过多,请求完调用close方法关闭连接,使用mongodb扩展后,默认使用长连接,且没有close方法,所以迁移时要评估改成长连接后的mongodb单台server的连接数,一般是单台php-fpm数量*机器数。
UTF-8编码兼容性问题
如果有非UTF-8编码的数据用mongo扩展可以读出来,用mongodb扩展读可能会抛异常(Detected corrupt BSON data), 这种一方面需要进行数据修复,另一方面需要堵住入口,避免出现此类问题。这种问题一般是在客户端发送的消息\、邮件里有特殊字符导致。
具体参考:https://github.com/mongodb/mongo-php-driver/pull/776
返回值差异
mongodb扩展isAcknowledged返回true不是代表成功,只是标识网络是OK的
mongodb里成功可以根据update,insert,remove具体操作对应的getModifiedCount, getInsertedCount, getDeletedCount等具体数量判断。
mongo update判断更新成功(生效)updatedExisting,但是mongodb 判断update是否成功建议用getMatchedCount,不能用getModifiedCount。举例,如果更新的内容并没有导致变化,updatedExisting返回1,getModifiedCount返回0,getMatchedCount返回1。
Nginx map使用
map 指令是由 ngx_http_map_module 模块提供的,默认情况下安装 nginx 都会安装该模块。
map 的主要作用是创建自定义变量,通过使用 nginx 的内置变量,去匹配某些特定规则,如果匹配成功则设置某个值给自定义变量。 而这个自定义变量又可以作于他用
下面举几个例子:
- 场景一: 匹配请求 url 的参数,如果参数是 debug 则设置 $foo = 1 ,默认设置 $foo = 0
map $args $foo {
default 0;
debug 1;
}解释:$args 是nginx内置变量,就是获取的请求 url 的参数。 如果 $args 匹配到 debug 那么 $foo 的值会被设为 1 ,如果 $args 一个都匹配不到 $foo 就是default 定义的值,在这里就是 0
语法:
map $var1 $var2 {...}map指令的三个参数:
- default : 指定源变量匹配不到任何表达式时将使用的默认值。当没有设置 default,将会用一个空的字符串作为默认的结果
- hostnames : 允许用前缀或者后缀掩码指定域名作为源变量值。这个参数必须写在值映射列表的最前面
- include : 包含一个或多个含有映射值的文件
在 Nginx 配置文件中的作用段: http{} ,注意 map 不能写在 server{} 否则会报错
- map 的 $var1 为源变量,通常可以是 nginx 的内置变量,$var2 是自定义变量。 $var2 的值取决于 $var1 在对应表达式的匹配情况。 如果一个都匹配不到则 $var2 就是 default 对应的值
- 一个正则表达式如果以 “~” 开头,表示这个正则表达式对大小写敏感。以 “~*”开头,表示这个正则表达式对大小写不敏感
map $http_user_agent $agent {
default "";
~curl curl;
~*apachebench" ab;
}- 场景二:接下来看看实际用法,之前在给项目做php7升级,开发环境装了php5和php7,按项目来逐步升级php7,如何让某些项目使用php5,某些项目使用php7呢?
upstream php56 {
server 127.0.0.1:9000;
}
upstream php72 {
server 127.0.0.1:9002;
}
map $uri $php_backend {
default php56;
~^/project1/ php72;
~^/project2/ php72;
~^/project3/ php72;
~^/project4/ php72;
....
}
....
location ~ .*\.(php|php5)?$ {
fastcgi_buffer_size 128k;
fastcgi_buffers 4 256k;
fastcgi_busy_buffers_size 256k;
fastcgi_pass $php_backend;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
fastcgi_param REQUEST_URI $new_request_uri;
fastcgi_intercept_errors on;
}用以上的方式,根据链接特征设置了php_backend变量,从而使用不同的端口处理