文章内容源于MySQL 8 Cookbook【这本书不错】
二进制日志包含数据库的所有更改记录,包括数据和结构两方面。二进制日志不记录SELECT 或 SHOW 等不修改数据的操作。运行带有二进制日志的服务器会带来轻微的性能影响。二进制日志能保证数据库出故障时数据是安全的。只有完整的事件或事务会被记录或回读。
1.首先第一个问题:为什么应该使用二进制日志?
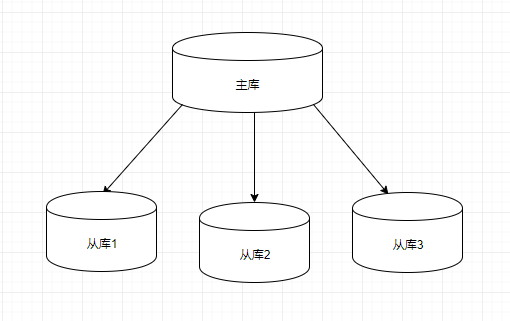
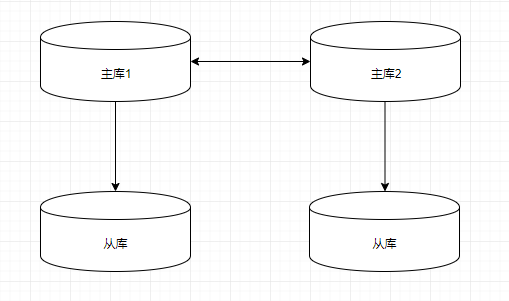
- 复制:使用二进制日志,可以把对服务器所做的更改以流式方式传输到另一台服务器上。从(slave)服务器充当镜像副本,也可用于分配负载。接受写入的服务器称为主(master)服务器。
- 时间点恢复:假设你在星期日的00:00进行了备份,而数据库在星期日的08:00出现故障。使用备份可以恢复到周日00:00的状态;而使用二进制日志可以恢复到周日08:00的状态。
2.启用binlog方法
要启用binlog,必须设置log_bin和server_id并重启服务器
例如log_bin设置为/data/mysql/binlogs/server1,二进制日志存储在/data/mysql/binlogs文件夹中名为server1.000001、server1.000002等日志文件中。每当服务器启动或刷新日志时,或者当前日志的大小达到max_binlog_size时,服务器都会在系列中创建一个新文件。每个二进制日志的位置都在server1.index文件中被维护
启用binlog代码如下:
shell> sudo vim /etc/my.cnf
[mysqld]
log_bin = /data/mysql/binlogs/server1
server_id = 100
如果log_bin不赋予任何值,在这种情况下,二进制日志是在数据目录中创建的。可以使用主机名作为目录名称
设置了log_bin,如果要生效,记得重启mysql
验证是否生效:
mysql> show variables like 'log_bin%';
log_bin On
log_bin_basename /data/mysql/binlogs/server1
log_bin_index /data/mysql/binlogs/server1.index
......
执行SHOW BINARY LOGS;或SHOW MASTER LOGS;,以显示服务器的所有二进制日志
执行命令SHOW MASTER STATUS;以获取当前的二进制日志位置:
mysql> show master status;
File Position
server1.000002 3273
一旦server1.00000x达到max_binlog_size(默认1G),一个新文件server1.00000x+1就会被创建,并被添加到server1.index中。可以动态设置max_binlog_size。
set @@global.max_binlog_size=xxxxxxxx
禁用会话的二进制日志
有些情况下我们不希望将执行语句复制到其他服务器上。为此,可以使用以下命令来禁用该会话的二进制日志:
mysql>set SQL_LOG_BIN = 0;
在这条语句后的所有SQL语句都不会被记录到二进制日志中,不过这仅仅是针对该会话的。要重新启用二进制日志,可以执行以下操作:
mysql>set SQL_LOG_BIN = 1;
移至下一个日志
可以使用FLUSH LOGS命令关闭当前的二进制日志并打开一个新的二进制日志:
mysql>flush logs;
清理二进制日志
随着写入次数的增多,二进制日志会消耗大量空间。如果放任不管,这些写入操作将很快占满磁盘空间,因此清理它们至关重要。1.使用binlog_expire_logs_seconds 和expire_logs_days 设置日志的到期时间。
如果想以天为单位设置到期时间,请设置 expire_logs_days。例如,如果要删除两天之前的所有二进制日志,请SET@@global.expire_logs_days=2。如果将该值设置为0,则禁用设置会自动到期。
如果想以更细的粒度来设置到期时间,可以使用binlog_expire_logs_seconds变量,它能够以秒为单位来设置二进制日志过期时间。
这个变量的效果和 expire_logs_days 的效果是叠加的。例如,如果expire_logs_days是1并且binlog_expire_logs_seconds是43200,那么二进制日志就会每 1.5 天清除一次。这与将binlog_expire_logs_seconds设置为129600、将expire_logs_days设置为0的效果是相同的。在 MySQL 8.0 中,binlog_expire_logs_seconds和expire_logs_days必须设置为0,以禁止自动清除二进制日志。
2.要手动清除日志,请执行PURGE BINARY LOGS TO ‘<file_name>’。例如,有server1.000001、server1.000002、server1.000003和server1.000004文件,如果执行 PURGE BINARY LOGS TO'server1.000004',则从server1.000001 到 server1.000003 的所有文件都会被删除,但文件server1.000004不会被删除:
除了指定某个日志文件,还可以执行命令PURGE BINARY LOGS BEFORE ‘2017-08-03 15:45:00’。除了使用BINARY,还可以使用MASTER。
mysql> PURGE MASTER LOGS TO ‘server1.000004’ 可以实现和之前语句一样的效果。
3.要删除所有二进制日志并再次从头开始,请执行RESET MASTER
binlog的格式
二进制日志可以写成下面三种格式。
1.STATEMENT:记录实际的SQL语句。
2.ROW:记录每行所做的更改。例如,更新语句更新10行,所有10行的更新信息都会被写入日志。而在基于语句的复制中,只有更新语句会被写入日志,默认格式是ROW。
3.MIXED:当需要时,MySQL会从STATEMENT切换到ROW。
有些语句在不同服务器上执行时可能会得到不同的结果。例如,UUID()函数的输出就因服务器而异。这些语句被称为非确定性的语句,基于这些语句的复制是不安全的。在这些情况下,当设置MIXED格式时,MySQL服务器会切换为基于行的格式。
可以使用兼具全局和会话范围作用域的动态变量binlog_format来设置格式。在全局范围进行设置可使所有客户端使用指定的格式:
mysql>set global binlog_format = 'statement';
mysql>set global binlog_format = 'row';
1.Statement:每一条会修改数据的sql都会记录在binlog中。
优点:不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。(相比row能节约多少性能与日志量,这个取决于应用的SQL情况,正常同一条记录修改或者插入row格式所产生的日志量还小于Statement产生的日志量,但是考虑到如果带条件的update操作,以及整表删除,alter表等操作,ROW格式会产生大量日志,因此在考虑是否使用ROW格式日志时应该跟据应用的实际情况,其所产生的日志量会增加多少,以及带来的IO性能问题。)
缺点:由于记录的只是执行语句,为了这些语句能在slave上正确运行,因此还必须记录每条语句在执行的时候的一些相关信息,以保证所有语句能在slave得到和在master端执行时候相同的结果。另外mysql 的复制,像一些特定函数功能,slave可与master上要保持一致会有很多相关问题(如sleep()函数, last_insert_id(),以及user-defined functions(udf)会出现问题).
使用以下函数的语句也无法被复制:
- LOAD_FILE()
- UUID()
- USER()
- FOUND_ROWS()
- SYSDATE() (除非启动时启用了 –sysdate-is-now 选项)
同时在INSERT …SELECT 会产生比 RBR 更多的行级锁
2.Row:不记录sql语句上下文相关信息,仅保存哪条记录被修改。
优点: binlog中可以不记录执行的sql语句的上下文相关的信息,仅需要记录那一条记录被修改成什么了。所以rowlevel的日志内容会非常清楚的记录下每一行数据修改的细节。而且不会出现某些特定情况下的存储过程,或function,以及trigger的调用和触发无法被正确复制的问题
缺点:所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容,比如一条update语句,修改多条记录,则binlog中每一条修改都会有记录,这样造成binlog日志量会很大,特别是当执行alter table之类的语句的时候,由于表结构修改,每条记录都发生改变,那么该表每一条记录都会记录到日志中。
3.Mixedlevel: 是以上两种level的混合使用,一般的语句修改使用statment格式保存binlog,如一些函数,statement无法完成主从复制的操作,则采用row格式保存binlog,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种.新版本的MySQL中队row level模式也被做了优化,并不是所有的修改都会以row level来记录,像遇到表结构变更的时候就会以statement模式来记录。至于update或者delete等修改数据的语句,还是会记录所有行的变更。
从二进制日志中提取语句:
使用mysqlbinlog程序可以从二进制日志中提取内容,并将其应用到其他服务器
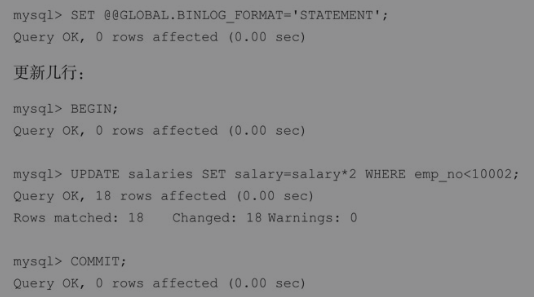
实操:使用各种二进制格式执行几条语句。如果把binlog_format设置为GLOBAL级别(全局范围),必须断开并重新连接,以使更改生效。如果想保持连接,请把binlog_format设置为SESSION级别(会话范围)。
更改为基于语句(statement)的的复制(SBR):
更改为基于行(Row)的复制(RBR):
更新几行:
改为mixed格式:
更新几行:
mysqlbinlog操作
要显示日志server1.000001的内容,请执行以下操作:
shell> mysqlbinlog /data/mysql/binlogs/server1.000001
你会得到类似下面的输出结果:
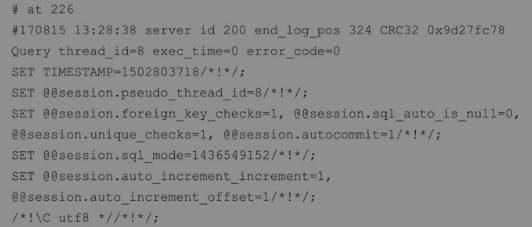
#at 206
#170815 12:49:24 server id 200 end log pos 312 CRC32 0x9197bf88 Query
thread_id exec_time=0 error_code=0
BINLOG '
~
~
在第一行中,#at后面的数字表示二进制日志文件中事件的起始位置(文件偏移量)。
第二行包含了语句在服务器上被启用的时间戳。
时间戳后面跟着 server ID、end_log_pos、thread_id、exec_time和error_code。
● server id:产生该事件的服务器的server_id值(在这个例子中为200)。
● end_log_pos:下一个事件的开始位置。● thread_id:指示哪个线程执行了该事件。
● exec_time:在主服务器上,它代表执行事件的时间;在从服务器上,它代表从服务器的最终执行时间与主服务器的开始执行时间之间的差值,这个差值可以作为备份相对于主服务器滞后多少的指标。
● error_code:代表执行事件的结果。零意味着没有错误发生。
回顾:
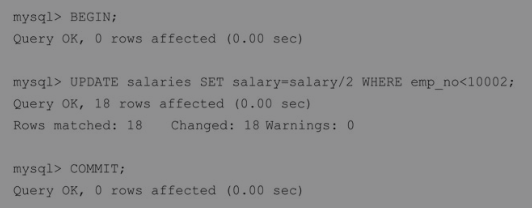
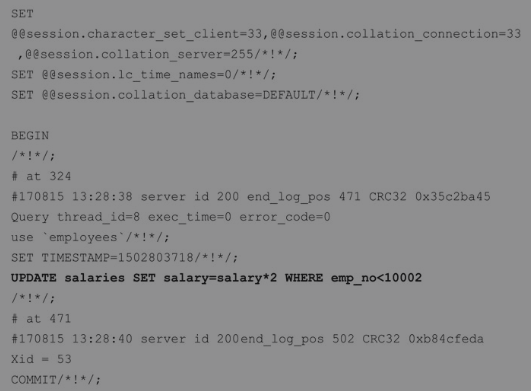
1.基于语句复制(SBR):我们在基于语句的复制中执行了UPDATE语句,而且在二进制日志中记录了相同的语句。除了保存在服务器上,会话变量也被保存在二进制日志中,以在从库上复制相同的行为:
2.当使用基于行的复制(RBR)时,会以二进制格式对整行(而不是语句)进行保存,而且二进制格式不能读取。此外,你可以观察长度,单个更新语句会生成很多数据。
3.当使用MIXED格式时,UPDATE语句被记录为SQL语句,而INSERT语句以基于行的格式被记录,因为INSERT有非确定性的UUID()函数:
提取的日志可以被传送给MySQL以回放事件。在重放二进制日志时最好使用force选项,这样即使force选项卡在某个点上,执行也不会停止。稍后,你可以查找错误并手动修复数据。
shell>mysqlbinlog /data/mysql/binlogs/server1.000001 | mysql -f -h <remote_host> -u <username> -p
或者也可以先保存到文件中,稍后执行:
shell> mysqlbinlog /data/mysql/binlogs/server1.000001 > server1.binlog_extract
shell> cat server1.binlog_extract | mysql -h <remote_user> -u <username> -p
根据时间和位置进行抽取我们可以通过指定位置从二进制日志中提取部分数据。假设你想做时间点恢复。假如在 2017-08-19 12:18:00 执行了 DROP DATABASE 命令,并且最新的可用备份是在2017-08-19 12:00:00 做的,该备份已经恢复。现在,需要恢复从 12:00:01 至2017-08-19 12:17:00 的数据。请记住,如果提取完整的日志,它还将包含 DROP DATABASE命令,该命令将再次擦除数据。可以通过–start-datetime和–stop-datatime选项来指定提取数据的时间窗口。
shell>mysqlbinlog /data/mysql/binlogs/server1.000001 --start-datetime="xxxx" --stop-datetime="yyyy" > binlog_extract
使用时间窗口的缺点是,你会失去灾难发生那一刻的事务。为避免这种情况,必须在二进制日志中使用事件的文件偏移量。一个连续的备份会保存它已完成备份的所有binlog文件的偏移量。备份恢复后,必须从备份的偏移量中提取binlog。我们将在第7章中详细了解备份。假设备份的偏移量为471,执行DROP DATABASE命令的偏移量为1793。可以使用–start-position和–stop-position选项来提取偏移量之间的日志:
shell>mysqlbinlog /data/mysql/binlogs/server.000001 --start-position=471 --stop-position=1793 > binlog_extract
请确保DROP DATABASE命令在提取的binlog中不再出现。基于数据库进行提取使用–database选项可以过滤特定数据库的事件。如果多次提交,则只有最后一个选项会被考虑。这对于基于行的复制非常有效。但对于基于语句的复制和MIXED,只有当选择默认数据库时才会提供输出。以下命令从employees 数据库中提取事件:
shell>mysqlbinlog /data/mysql/binlogs/server1.000001 --database=employees > binlog_extract
正如mysql 8文档中所解释的,假设二进制日志是通过使用基于语句的日志记录执行这些语句而创建的:
mysql>
INSERT INTO test.t1 (i) VALUES (100);
INSERT INTO db2.t2 (j) VALUES (200);
use test;
INSERT INTO test.t1(i) VALUES (101);
INSERT INTO t1(i) VALUES (102);
INSERT INTO db2.t2(j) VALUES (201);
use db2;
INSERT INTO test.t1(i) VALUES (103);
INSERT INTO db2.t2(j) VALUES (202);
INSERT INTO t2 (j) VALUES (203);
mysqlbinlog –database=test 不输出前两个 INSERT 语句,因为没有默认数据库。
mysqlbinlog –database=test 输出USE test后面的三条INSERT语句,但不是USE db2后面的三条INSERT语句。
因为没有默认数据库,mysqlbinlog –database=db2 不输出前两条INSERT语句。mysqlbinlog –database=db2不会输出USE test后的三条INSERT语句,但会输出在USE db2之后的三条INSERT语句。
提取行事件显示
默认情况下,基于行的复制日志显示为二进制格式。要查看行信息,必须将–verbose或-v选项传递给mysqlbinlog。行事件的二进制格式以注释的伪SQL语句的形式显示,其中的行以###开始。可以看到,单个更新语句被改写为了每行的UPDATE语句。
shell> mysqlbinlog /data/mysql/binlogs/server1.000001 --start-position=660 --stop-position=1298 -v
~
~
# at 660
#170815 13:29:02 server id 200 end_log_pos 722 CRC32 0xe0a2ec74
Table_map: `employees`.`salaries` mapped to number 165
# at 722
........
BINLOG *
二进制内容......
........
### update `employeeds`.`salaries`
### where
### @1=1001
### @2=240468
### @3='xxxxx'
### @4='zzzzzz'
###SET
### @1=1001
### @2=xxxx
.....
如果你只想查看没有二进制行信息的伪 SQL 语句,请指定–base64-output=”decode-rows”以及–verbose:
shell>mysqlbinlog /data/mysql/binlogs/server.00001 --start-position=xxx --stop-position=xxxx --verbose --base64-output="decode-rouws"
重写数据库名称
假设你想将生产服务器上的employees 数据库的二进制日志恢复为开发服务器上的employees_dev,可以使用–rewrite-db=‘from_name-> to_name’选项。这会将所有from_name重写为to_name。
shell>mysqlbinlog /data/mysql/binlogs/server1.000001 --start-position=xxx --stop-position=yyyy --rewrite-db='employees->employees_dev'
在恢复时禁用二进制日志
在恢复二进制日志的过程中,如果你不希望mysqlbinlog进程创建二进制日志,则可以使用–disable-log-bin选项:
shell>mysqlbinlog /data/mysql/binlogs/server1.00001 --start-position=xxx --stop-position=yyyy --disable-log-bin > binlog_restore
可以看到SET @OLD_SQL_LOG_BIN=@@SQL_LOG_BIN, SQL_LOG_BIN=0 被写到binlog_restore里,这样可以防止创建binlog
忽略要写入二进制日志的数据库
可以通过在my.cnf中指定–binlog-do-db=db_name选项,来选择将哪些数据库写入二进制日志。要指定多个数据库,就必须使用此选项的多个实例。由于数据库的名字可以包含逗号,因此如果提供逗号分隔列表,则该列表将被视为单个数据库的名字。需要重新启动MySQL服务器才能使更改生效。
迁移二进制日志
由于二进制日志占用越来越多的空间,有时你可能希望更改二进制日志的位置,可以按照以下步骤操作。单独更改 log_bin 是不够的,必须迁移所有二进制日志并在索引文件中更新位置。mysqlbinlogmove工具可以自动执行这些任务,简化你的工作。
具体操作:
先安装MySQL工具集,以使用mysqlbinlogmove脚本
1.systemctl stop mysql
2.mysqlbinlogmove --bin-log-basename=server1 --binlog-dir=/data/mysql/binlogs /binlogs
3.vim /etc/my.cnf
[mysqld]
log_bin=/binlogs
4.systemctl start mysql
将二进制日志从/data/mysql/binlogs更改为/binlogs,则应使用上面命令。如果base name不是默认名称,则必须通过–bin-log-basename 选项设定base name